Case Study
Problem Domain
1. Introduction
Seamless is an open-source, low-configuration CI/CD (Continuous Integration and Continuous Delivery/Deployment) framework that streamlines the development and deployment of containerized microservice applications. It automates the building, testing, and deployment of code, enabling developers to deliver software quickly and reliably. Seamless links multiple microservices to a single shared pipeline, eliminating the need to maintain a separate pipeline per service. Throughout this case study, we’ll explore how the deployment process has evolved over time, the role of CI/CD, and how we designed Seamless to support our desired use case.
2. Evolution of Deployment Processes
A deployment process refers to the steps required to make an application accessible to end users. Companies typically care about their deployment process because it impacts:
- The speed at which software can be delivered to end users.
- The confidence the company can have that high-quality, functional code is released.
The deployment process is initiated with a change in the source code and advances through building, testing, and deploying the code. Most modern companies manage source code through a version control system.
2.1 Version Control Systems
Version control systems (VCS) such as Git enable developers to collaborate on a single, centralized repository.1 By creating branches, developers can work on changes independently. After a change is complete, it is typically merged into a central branch called main or master. This is where the deployment process begins.
While most deployment processes utilize a version control system, the path from version control to deployment can be either manual or automatic.
2.2 Traditional Manual Deployment Processes
A manual deployment process consists of human-executed steps, like updating configuration files, copying files to production environments, and restarting servers.
In the past, manual deployments were common because automation tools were either unavailable or unsophisticated. Despite advances in automation, many companies still have outdated, manual deployment processes because of the time and effort required to adopt automation.
Two key factors prompted a movement away from manual deployment processes: speed and reliability.
Speed
One of the central issues with manual deployments is that they are time-consuming.
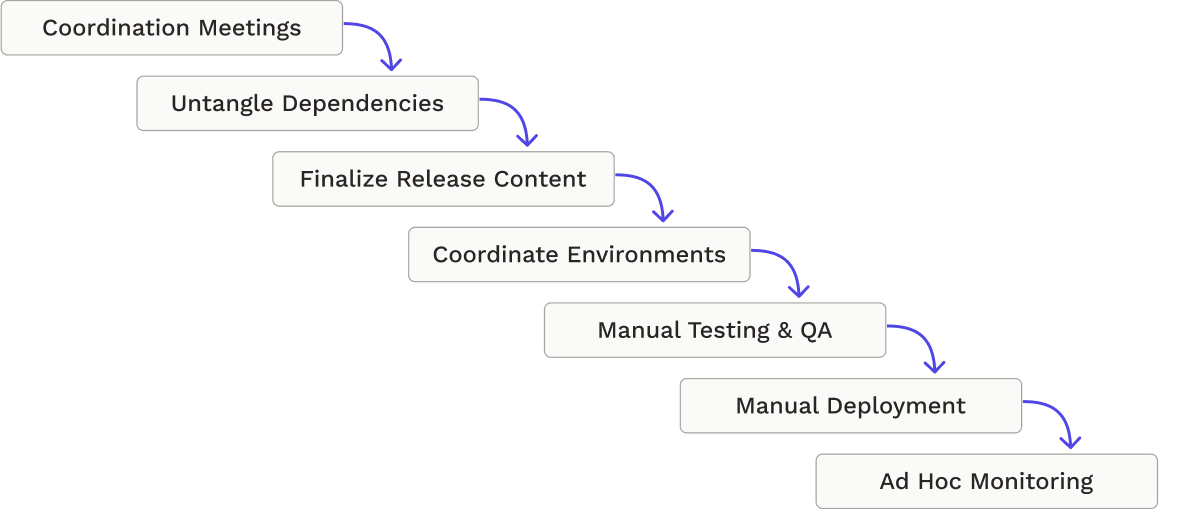
Firstly, there is usually a delay between the request for deployment and the start of the deployment. New commits sit idle in version control until the team responsible for deployment kicks off the deployment process. In some cases, developers must notify of new changes well before deployment dates. For example, TrueCar’s manual deployment strategy involved “Change Management tickets,” which each team had to file eight days before deployment.2

Once the deployment process commences, sometimes a long series of manual tasks is required to bring the code to production. This includes running scripts, checking code quality, and monitoring progress. If there are multiple teams responsible for different parts of the deployment process, they need to coordinate their efforts, causing additional delays.
Reliability
The second major pitfall of manual deployments is that they are error-prone. Firstly, humans are bad at performing rote activities in a consistent, reliable manner, leading to errors when configuring servers, setting up environments, and performing tests.
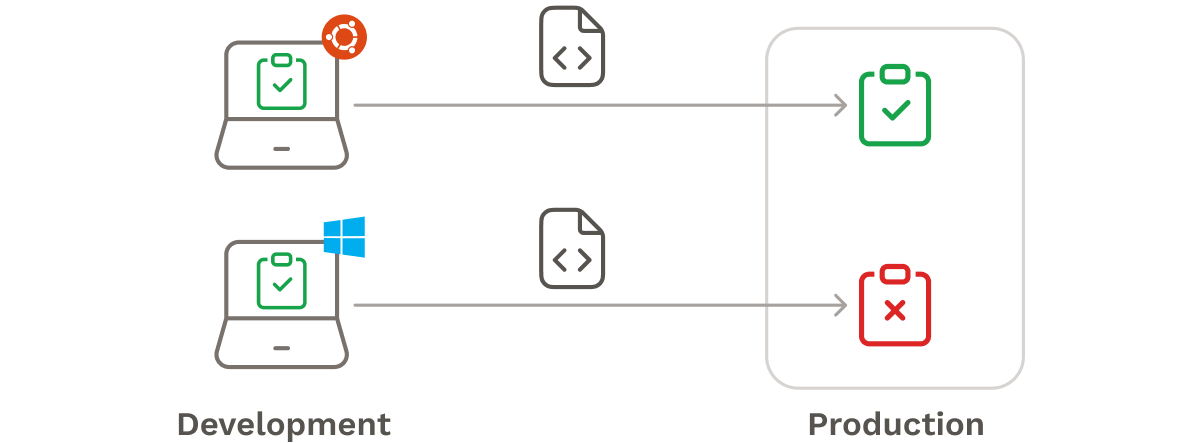
In addition to inconsistent administration of deployment steps, manual deployments are often run from inconsistent environments. Traditionally, manual deployments do not utilize a centralized system to build, test, and deploy developers' code. Instead, developers build and test applications on their local machines, each potentially having operating systems and environments that are different from one another and, by extension, the production environment.3 As a result, the application may function correctly when a developer tests it locally, but not in production.
Still, there are some useful aspects to traditional manual deployment processes. For example, requiring human intervention can be a useful safety check against deploying buggy or low-quality code.
2.3 Automated Deployment Processes
Over time, many companies began to introduce automation into their deployment process. An automated deployment process is commonly called a deployment pipeline. A deployment pipeline runs in a repeatable, consistent manner, resulting in faster and more reliable deployments.
Speed
The automation starts with version control. In automated deployments, version control systems are more than code storage locations: they plug directly into deployment pipelines. When a commit is made to a repository, the version control system can automatically trigger the deployment pipeline. This eliminates delays between deployment requests and pipeline initiation.
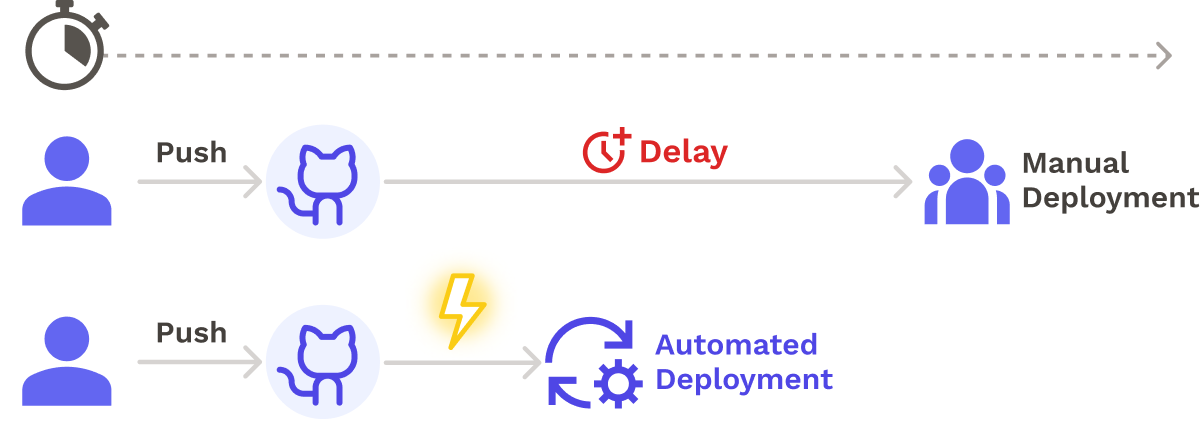
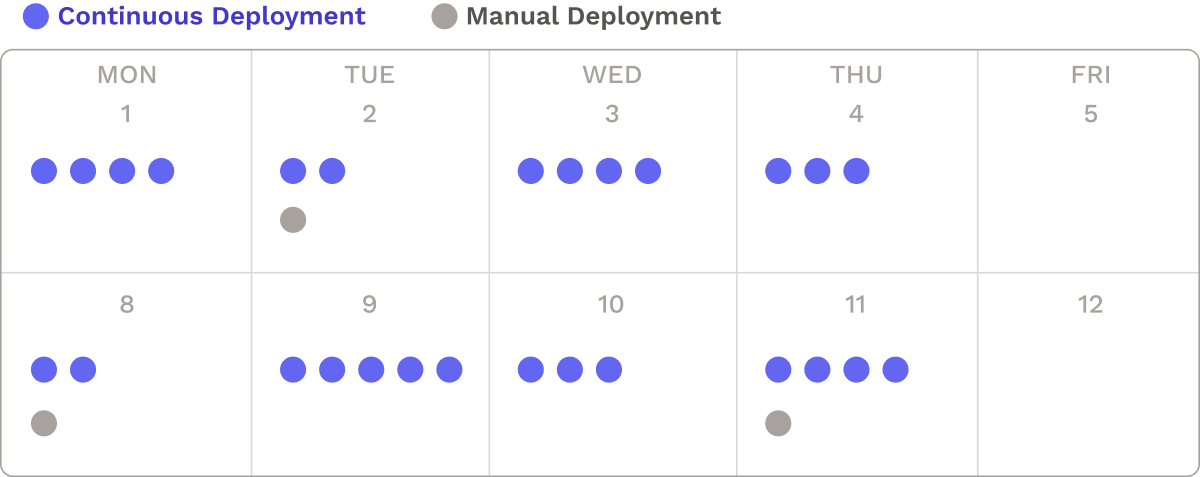
Deployment pipelines that fully automate all steps from source through production can drastically shorten the time between release cycles. For example, once TrueCar switched to a fully automated pipeline, they transitioned from a “burdensome weekly release cycle to deploying code up to 100 times per week”.4
Reliability
Automated deployment processes also ensure greater reliability by eliminating the need for human intervention and integrating tests and quality checks directly into the pipeline. Unlike manual deployments, automated deployment tasks are executed consistently; there is no chance of “forgetting” to perform a task. For example, automating testing consistently ensures bugs are identified early on.
Moreover, deployment pipelines address the environmental inconsistency issues found in classic manual deployments. They typically use dedicated machines, like a build server, to automatically carry out pipeline jobs. This eliminates the "it works on my machine" syndrome that is all too common in traditional manual deployments. If the code doesn’t work on the build server, it won't make it to production.
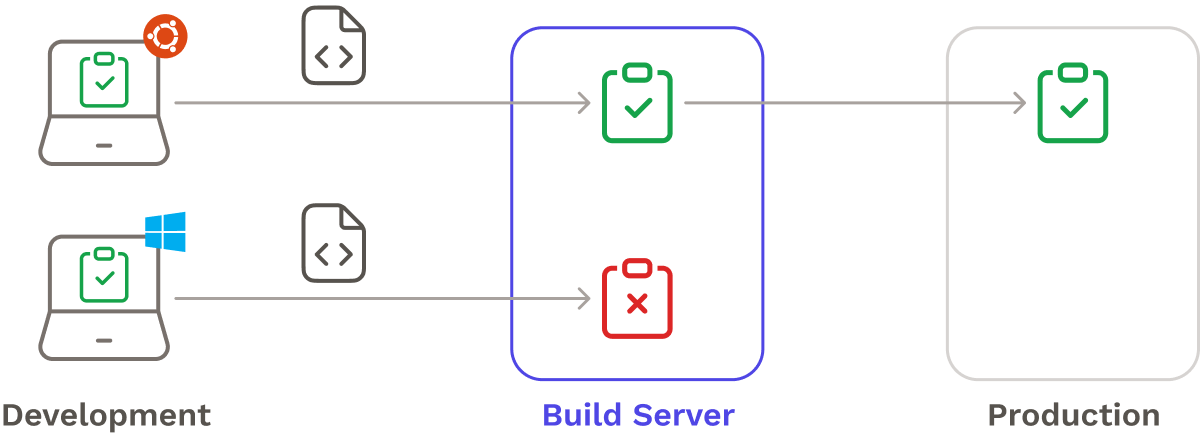
While automated deployment pipelines offer many advantages, transitioning from manual to automated deployments can be difficult. Resistance to change and extensive planning are common hurdles for many companies,5 and setting up deployment pipelines can be complex and demanding, as we’ll see later.
When introducing automation into their deployment processes, companies are typically striving to meet at least one of the following objectives: continuous integration, continuous delivery, and continuous deployment.
3. CI/CD Pipelines
As a whole, CI/CD refers to the process of continuously integrating code changes into a central repository and moving them closer to production. CI/CD can be broken down into a few parts.
- Continuous Integration (CI) is the practice of regularly merging code into the main branch of a central repository after the code is tested and built.
- Continuous Delivery (CD) extends upon continuous integration by continuously taking the new build and preparing it for release.6
- Continuous Deployment is the hallmark of a well-established CI/CD system: builds are immediately released into production.7
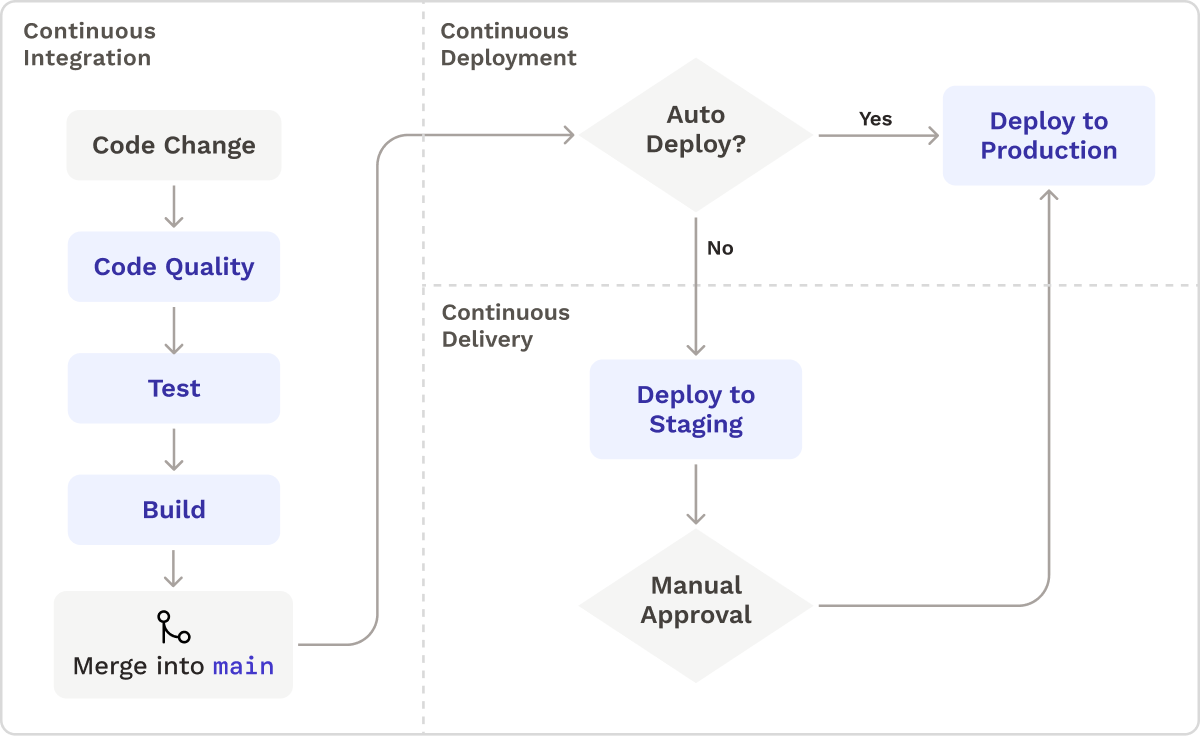
3.1 Stages of a CI/CD Pipeline
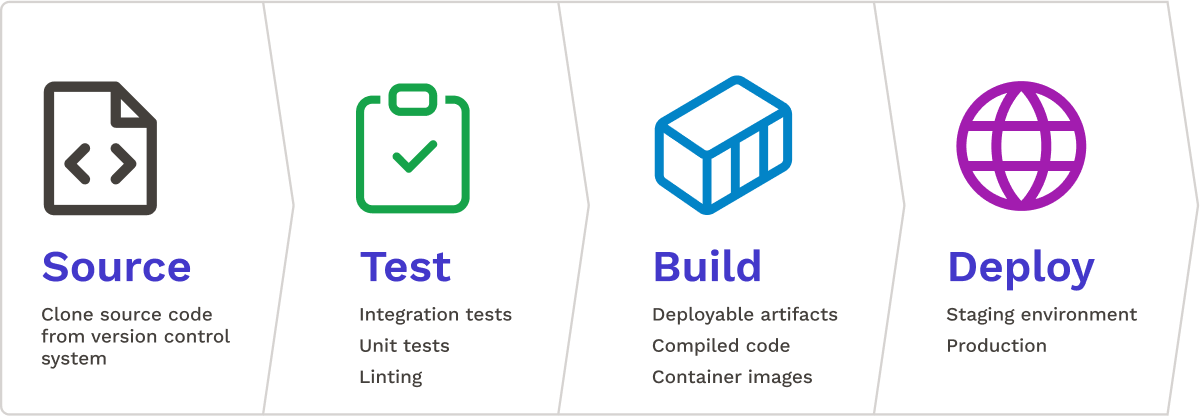
A deployment pipeline is essential for delivering code changes from development to production. Although there is no one-size-fits-all pipeline, they are typically broken up into four stages:8
The Source stage connects the pipeline to a repository hosting platform such as GitHub. Specified triggers such as opening a pull request or merging into main will initiate the pipeline.9
The Test stage executes tests against the updated application to ensure code quality and functionality. Standard forms of testing include static code analysis, unit testing, and integration testing. Static code analysis checks for stylistic issues and basic programmatic vulnerabilities; tools include ESLint and RuboCop. Unit testing verifies the functionality of code components individually; tools include Jest and RSpec. Integration testing confirms proper interactions between application components; tools include Cypress and Selenium.
The Build stage bundles the updated source code with its dependencies into a single deployable artifact; tools include Webpack and Docker.
The Deployment stage pushes the built artifact to one or more environments. Typically, this includes a Staging (Pre-Production) environment used by QA teams to review the application and give approval, as well as a Production environment that is accessible to end users and represents the final outcome of the deployment process. Examples of deployment destinations are Amazon Web Services (AWS) Fargate and Google Cloud Run.
Most deployment pipelines incorporate the stages outlined above. However, as companies adopt continuous integration, delivery, and deployment practices to different extents, they must consider a new tradeoff: how to balance safety with velocity.
4. Balancing Safety and Velocity
Practitioners of automated deployment usually need to make a tradeoff. A highly automated process gets code to production fast, but it may increase the likelihood of bugs entering production. On the flip side, a safer deployment process with more manual checks can reduce velocity. Teams can make a number of decisions to optimize the location of their deployment pipeline on a spectrum of balancing safety with velocity.
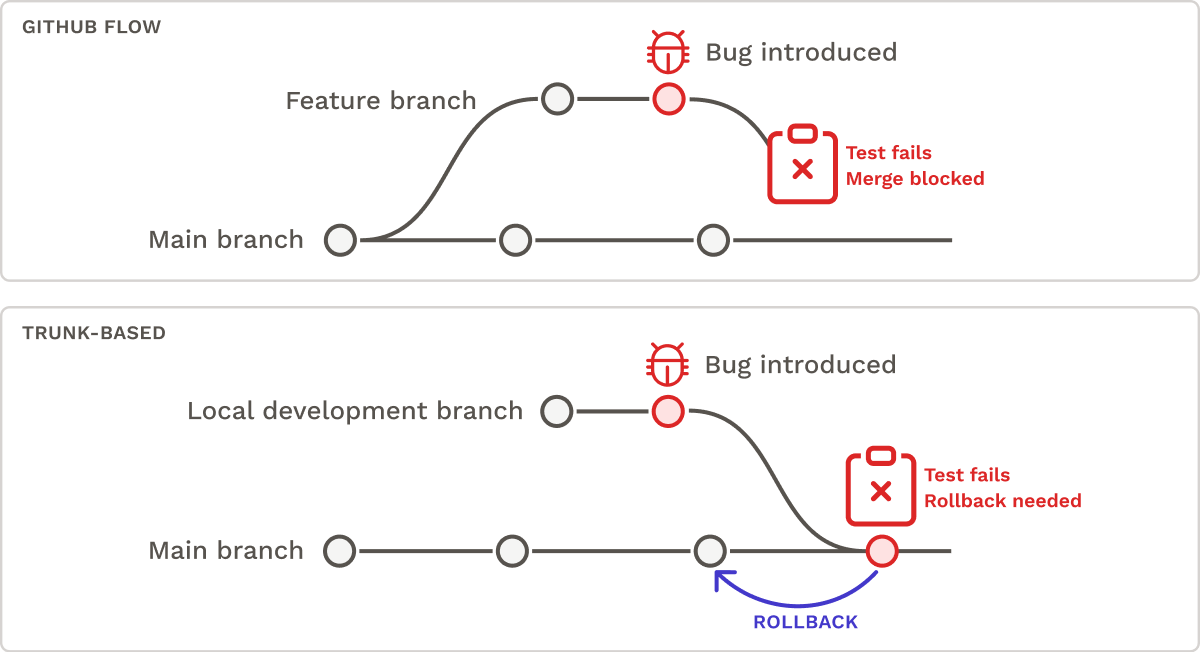
- Branching Strategy: Traditional feature branching workflows such as Github Flow prioritize safety by reducing the risk of untested code being pushed to main. In contrast, trunk-based development prioritizes speed by encouraging direct commits to main.10 However, if a bug is introduced in a trunk-based development workflow, it may necessitate a rollback to restore the code to its previous state.
- Merging Strategy: Deployment workflows can either automate the merging of pull requests when it passes status checks or require a manual merging process by a team member. Although auto-merging can speed up the pipeline, it introduces the risk of merging code that has not undergone adequate testing and review.

- Staging Environment: Teams continuously deploy code to production or first deploy to a staging environment. In the case of continuous deployment, code that passes status checks is deployed straight to production without manual approval. This allows teams to deliver updates to end users quickly but increases the likelihood that production-time adjustments may need to be performed, such as rolling back to a previous deployment.
To summarize, companies can enhance the speed of their CI/CD pipeline by implementing a trunk-based development workflow, automating code merging, and continuously deploying code. Alternatively, they can improve deployment safety by following a feature-branch workflow, mandating human code reviews before merging, and deploying to a staging environment before deploying to production.

While CI/CD pipelines can be adapted to meet different goals in terms of speed and safety, they can also be adapted to support different application architectures, such as monoliths and microservices.
5. CI/CD for Monoliths and Microservices
There is no universal CI/CD pipeline that suits every scenario. To understand why CI/CD pipelines vary for monoliths and microservices, we must examine a few fundamental differences between the two.
A monolith is a single unit containing tightly-coupled components. A microservices architecture consists of independent, loosely coupled services distributed across the network. The monolith has historically been the dominant approach to building applications, but this has shifted toward microservices out of a need for agility and scalability. To understand how CI/CD pipelines differ for monoliths and microservices, we will first explore the differences in the architectures themselves.
5.1 Different Deployment Methods
For monoliths, the entire codebase is packaged into a single executable file or directory that is deployed to production.11 In contrast, microservices are deployed as smaller, independent units.12 Due to their size, microservices can be packaged, tested, and deployed much more efficiently than a monolith, enabling small, frequent updates to be made. Furthermore, microservices are fully decoupled so each service can be deployed on its own schedule without impacting the others.
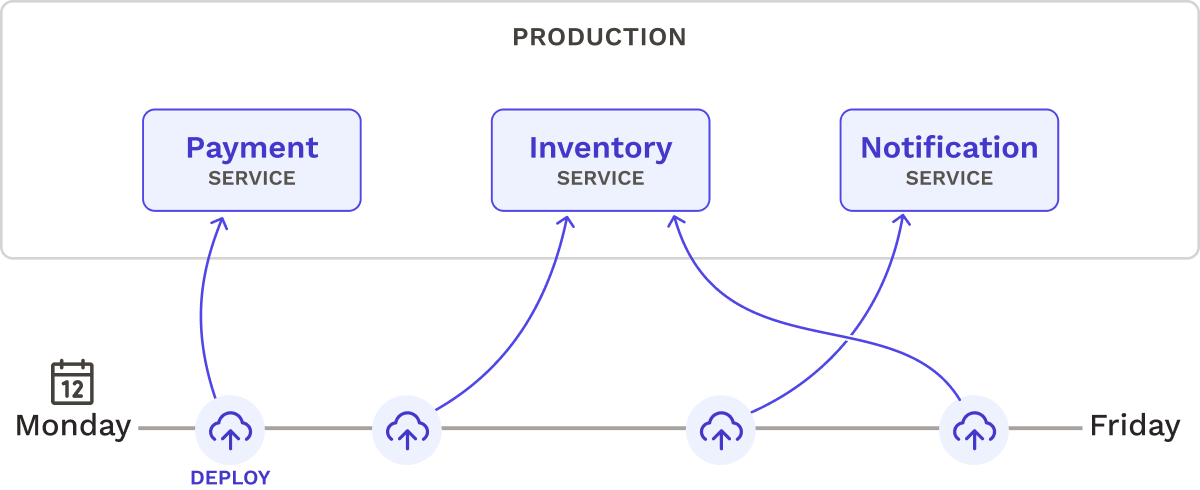
Consider three services: a Payment, Inventory, and Notification Service. Deployments of each service could take place on different days of the week:
5.2 Different Communication Methods
All components of a monolith run within the same application. As a result, the application’s modules communicate with function calls. In contrast, microservices communicate remotely with network calls (e.g. using HTTP). Unlike function calls, which are fast and reliable, network calls are susceptible to latency and unreliability. As we’ll discuss in a bit, these varying communication styles influence testing techniques for a CI/CD pipeline.
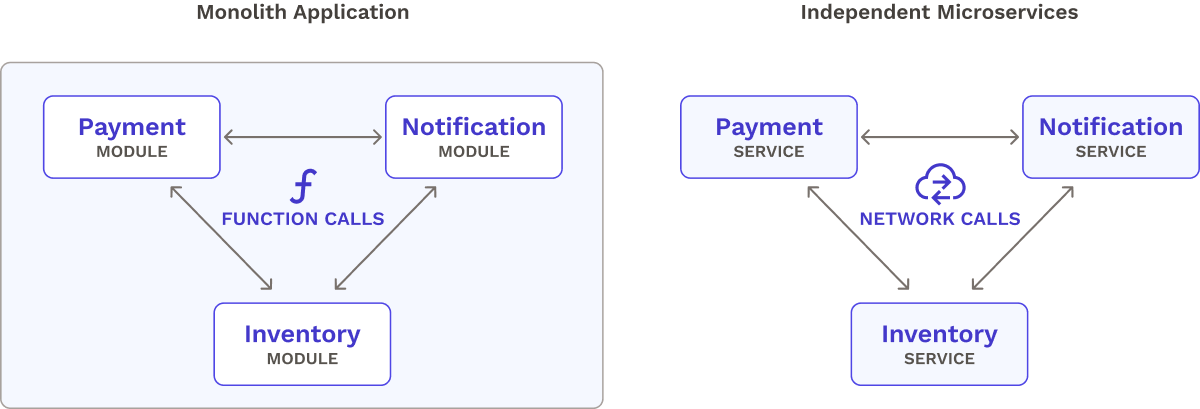
The distinct traits of microservices have implications for their CI/CD pipelines. Two defining characteristics of microservice architectures are their independent deployments and network-based communication methods. These two characteristics introduce two corresponding challenges for microservice-based CI/CD pipelines: managing pipelines for many microservices and conducting inter-service testing across the network.
6. CI/CD Challenges with Microservices
In this section, we’ll explore the specific challenges faced by CI/CD pipelines for microservices.
6.1 Pipeline Management Difficulties
The Many-Pipeline Problem
One approach to fully decoupling microservice deployments is to attach an individual CI/CD pipeline to each service. Since microservice teams are usually autonomous, it is common for teams to build their own pipelines. This gives each team full control of the pipeline and its stages.
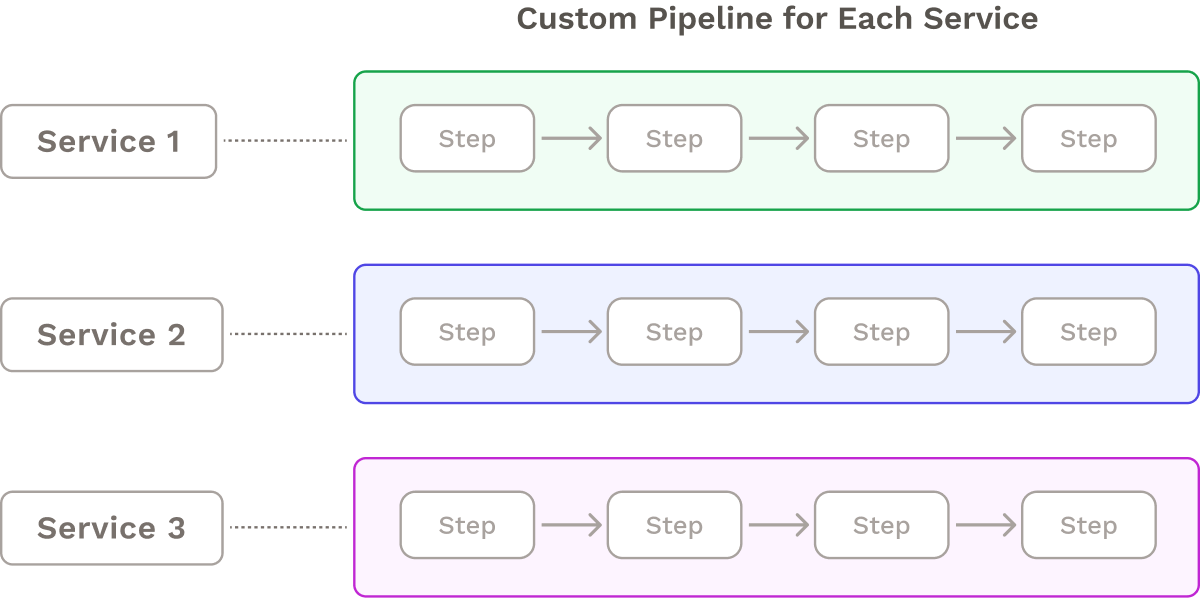
However, this many-pipeline approach adds complexity. There are multiple pipelines to maintain, along with their associated YAML files, scripts, and library versions. For example, when Expedia experienced an “explosion in the number of CI/CD pipelines”, the engineering teams found that they were “constantly needing to update” the pipelines for each microservice.13
Furthermore, while microservices usually have decentralized teams, there still often exists a central team overseeing the pipelines.14 This central team may struggle to keep up with the specifics of building, testing, and deploying each microservice. Consequently, it can be challenging to quickly make system-wide adjustments, such as rolling back a buggy microservice that has caused issues in the production environment.
To ease the burden of managing deployment pipelines for tens or hundreds of microservices, modularization techniques have emerged.
The Shared Step Solution
One solution for modularizing CI/CD pipelines across microservices is to reuse steps for different microservice pipelines. These shared steps could come in the form of shell scripts, reusable Docker images, repositories or libraries, or YAML templates.
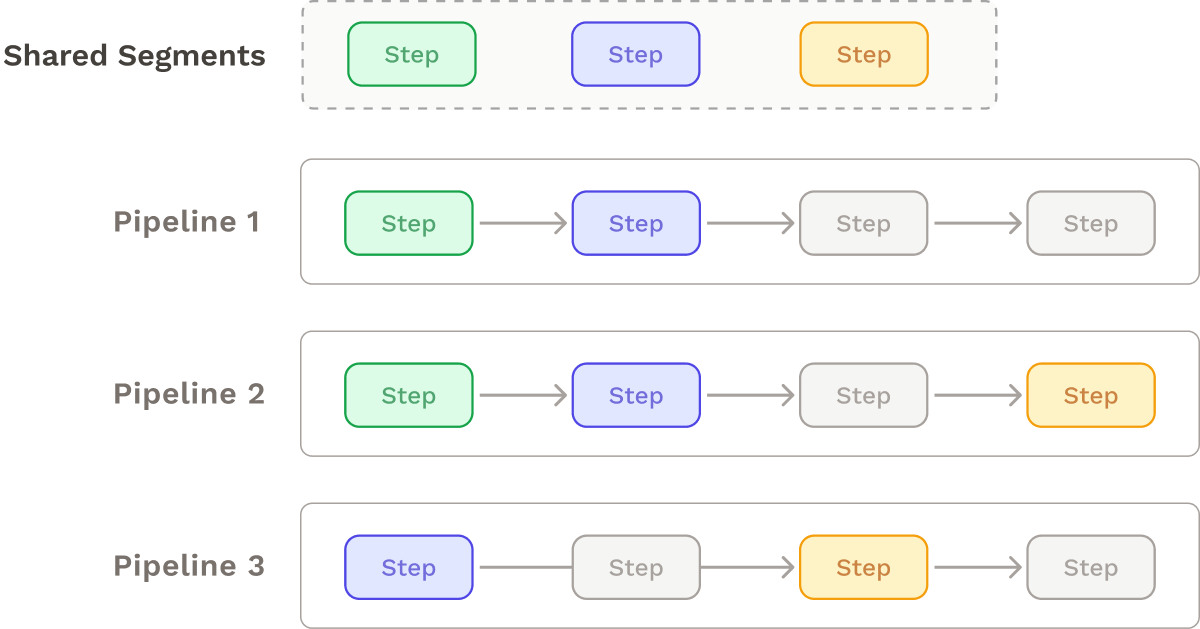
This approach can help eliminate redundancies across pipelines, keeping them “DRY”.15 Shared libraries prove particularly useful for microservices that have distinct deployment requirements but still share some common elements like utility functions and customized steps.
However, there are some major downsides to this approach. For one, it still requires bootstrapping and maintaining an individual pipeline for each microservice, and the shared pipeline steps themselves need to be maintained. Furthermore, this approach frequently results in version conflicts, where a shared step may contain a library that is compatible with certain microservices but not with others.16
Let’s look at a different strategy that mitigates some of these complications.
The Single, Parameterized Pipeline Solution
The former approach assumes that each microservice must have its own dedicated CI/CD pipeline. An alternative approach is to create a single, reusable, parameterized pipeline that is passed context whenever it is executed. This means that the pipeline is flexible: instead of linking pipelines to fixed repository URLs, testing commands, and configuration file entry points, these values can be configurable for each service. Adding a new microservice to the pipeline is simply a matter of filling in these parameters.17
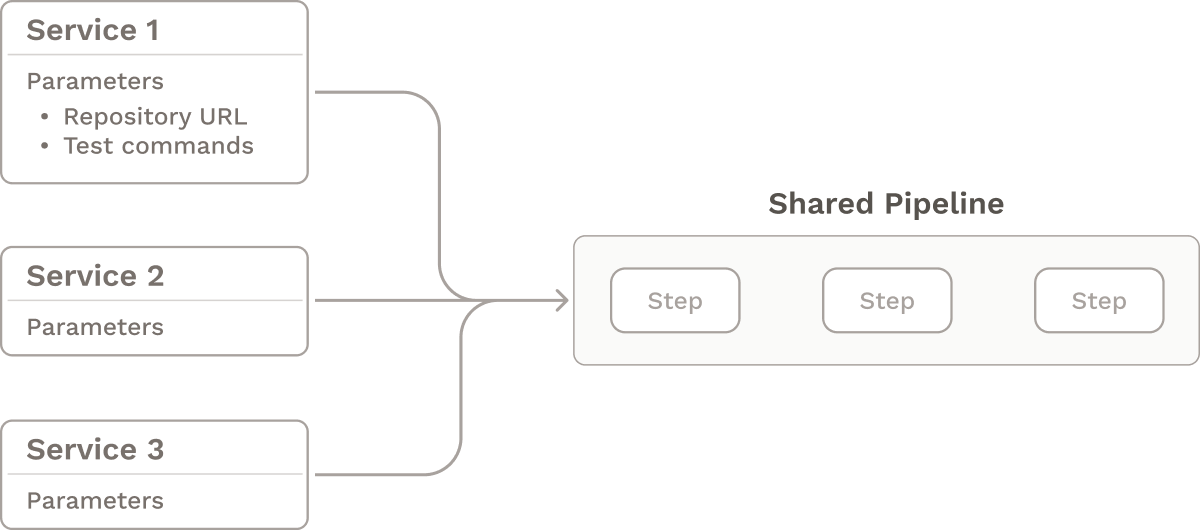
While this single-pipeline approach can simplify building and maintaining CI/CD pipelines, it may not be the best fit for every team. To make it work, there must be a certain degree of uniformity in terms of how each service is built, tested, and deployed. For example, every microservice might need to be deployed to the same Kubernetes cluster. For microservices with more heterogeneous deployment requirements, a different approach may be needed.
Along with issues of managing CI/CD pipelines for microservices, there are also unique challenges with testing microservices.
6.2 Microservice Testing Challenges
Testing microservices and their interactions is essential for ensuring that the system functions correctly, but it can be challenging due to their distributed nature.18 Unlike monolithic applications that run as a single entity, microservices are split across a network, so any tests that involve multiple services require making network calls. Consequently, testing strategies that were applied to monolithic applications may need to be reconsidered for microservices. Despite this challenge, it is crucial to test microservices in isolation, together, and as a whole system to ensure their proper functioning.
Solutions for Testing Microservices
There are several techniques available for testing at different levels of granularity. Here are some of the essential ones:19
- Unit Testing involves testing atomic units of a single service, such as its functions or classes, without relying on other services. However, it does not verify the interactions between services. Any services required for a unit test are mocked.
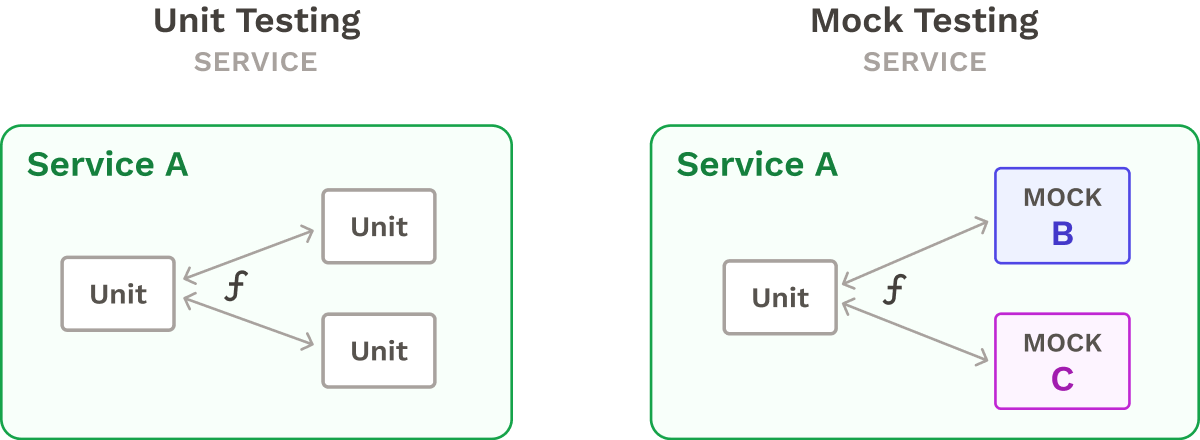
Integration Testing involves making network calls to test multiple services functioning together as a single subsystem. This technique may not be as precise as unit testing, but it can validate the larger behavior of whole subsystems. Integration Testing does not typically test the system as a whole.
On-Demand Staging Environments replicate production conditions and include all the microservices in the system. Although not a formal testing strategy, developers can use staging environments to test the system end-to-end, without getting bogged down in the details of each service and inter-service communications. However, staging environments can be resource-intensive.
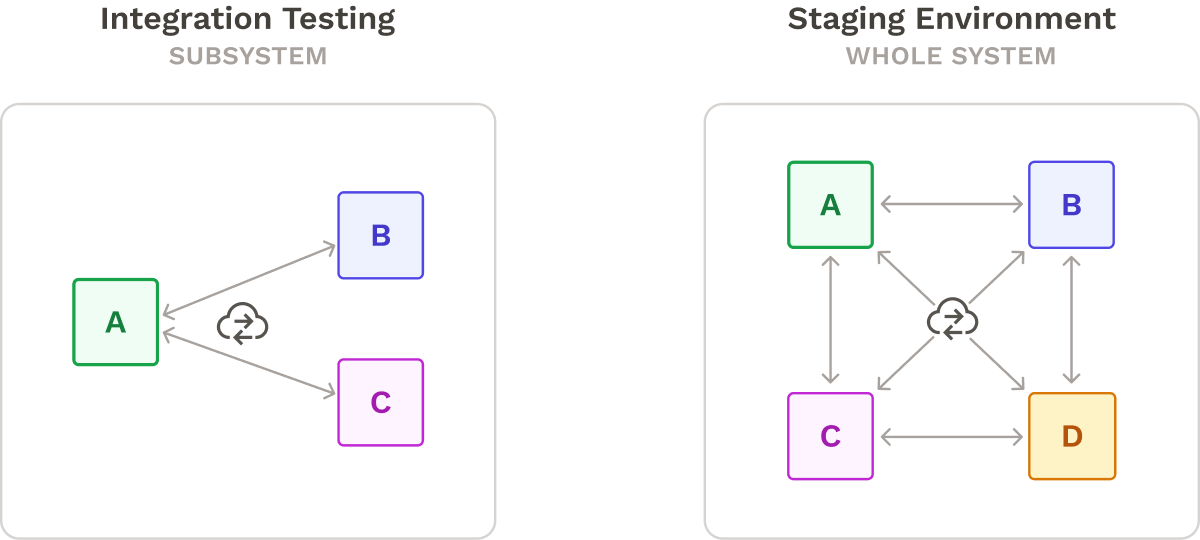
In practice, a comprehensive testing strategy will usually incorporate a combination of these testing strategies in order to increase confidence and test coverage.
Development teams using a manual deployment process for microservices might be looking to reap the benefits of automated deployments. One option development teams may consider is to build their own CI/CD pipeline
7. Manually Building a CI/CD Pipeline for Microservices
Building a CI/CD pipeline from scratch can be time-consuming and difficult, especially if it needs to handle the inherent complexities of a microservices architecture. Smaller teams with limited experience with cloud infrastructure and automation may struggle to architect a robust pipeline. They might also lack the staff and expertise to maintain and optimize it. The following is an example list of tasks for setting up a pipeline on AWS (we definitely don’t expect you to read everything, though you’re welcome to).
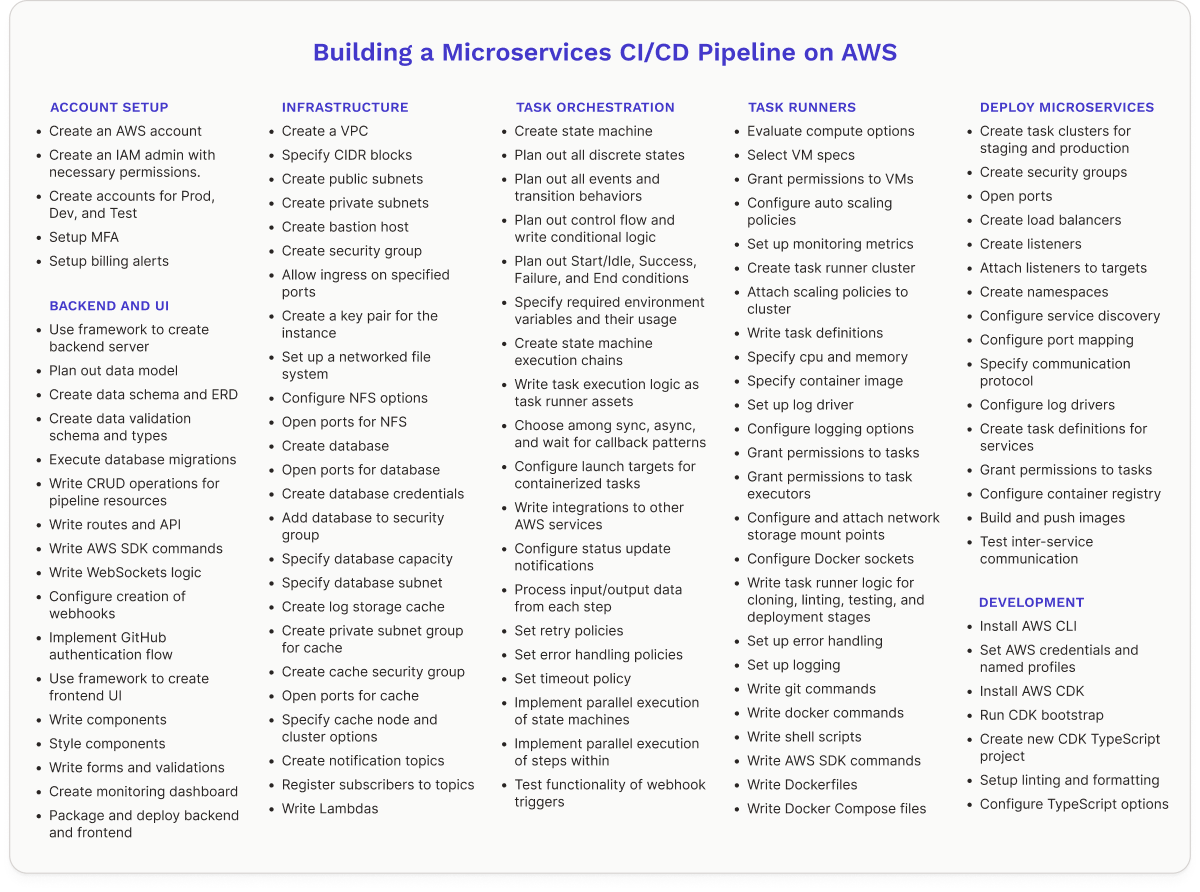
Instead of investing significant time and effort into this project, teams may choose to leverage existing CI/CD solutions to simplify the process.
8. Existing Solutions
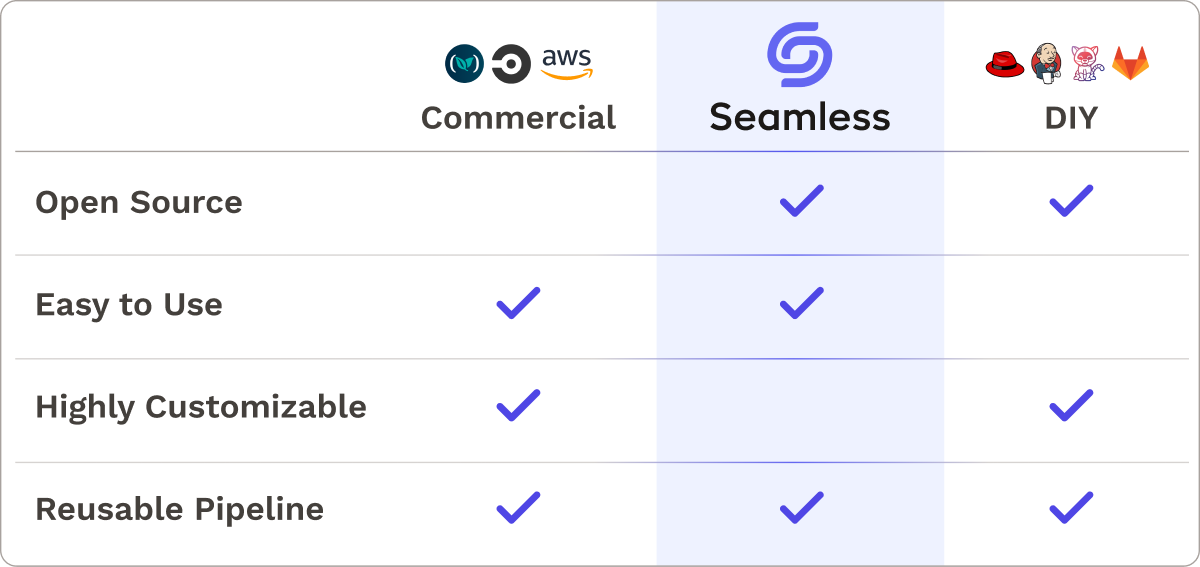
Existing solutions typically fall into two categories: DIY solutions and commercial solutions.
8.1 DIY Solutions
For organizations with more complex CI/CD pipeline setups, DIY solutions might be the best fit. There are many free open-source DIY CI/CD tools such as Jenkins, Ansible, Gitlab, and Tekton. These tools offer a high level of customization and control, allowing the tool to be tailored to a specific use case. For example, Jenkins achieves this customizability through its extensive plugin library.20
Many DIY tools also allow for pipeline modularization and reusability. Jenkins accomplishes pipeline modularization through shared libraries while Tekton allows for the reusability of different subcomponents, such as tasks and pipelines.21
While DIY solutions like Jenkins and Tekton offer a high degree of customization, they do require users to have a certain level of expertise in the relevant technologies. This means that teams with less experience in CI/CD may find them challenging to use, as they require users to make decisions about plugins, integrations, and deployment options. For example, with Jenkins, users must have knowledge of relevant plugins and be comfortable maintaining their own infrastructure. Likewise, Tekton requires experience with Kubernetes to set up and use effectively.
While companies with CI/CD expertise might be equipped to build customized pipelines, less established teams might reach for a Software as a Service (SaaS) product to help manage their CI/CD needs.
8.2 Commercial Solutions
There are various commercial CI/CD pipelines available such as Codefresh, Semaphore, CircleCI, and AWS CodePipeline. While not typically as flexible as open-source tools, these solutions do generally provide a degree of customization. For instance, YAML configuration files are commonly used to configure pipelines and their stages.
Some commercial CI/CD solutions offer pipeline modularization and reusability. With CodeFresh, a single pipeline can be linked to multiple repositories, or “triggers”. Environment variables associated with each trigger can then be passed to the pipeline at execution time. Meanwhile, Semaphore offers a “monorepo” approach, enabling multiple applications stored in a single repository to access the same CI/CD pipeline.
Some commercial CI/CD solutions provide microservice-specific testing solutions. For example, in order to test one service against other services, Codefresh allows the user to specify “sidecar containers” that will spin up during specified stages of the pipeline.
Commercial solutions are not suitable for the CI/CD needs of all teams. They are typically not as extensible as open-source solutions, making them unsuitable for certain use cases. And despite being generally easier to use than DIY tools, they usually still require setting up and configuring pipelines.
8.3 A Solution for Our Use Case
We wanted to build a tool for a specific use case: companies with a lower employee count that have embraced a containerized, microservices approach, seeking an uncomplicated solution for managing their CI/CD pipelines across their microservices.
While microservice architectures are commonly associated with large enterprises such as Netflix, some startups and small teams utilize a microservice-first approach. Startups that value fast feedback cycles often turn to microservice architectures as they allow for the release of incremental updates to microservices in isolation.22 Furthermore, startups anticipating a need to scale might adopt microservices early on because small microservices are easier to scale independently than a giant monolith.23
An example of this is Sortal, a digital asset management product built by a startup using microservices. Despite being a small application, Sortal still had “a lot of [deployment] processes to manage, especially for a small team.”24 Sortal’s small team overcame this complexity by utilizing a centralized, automated pipeline that enabled them to continuously deploy their application. We sought to assist companies with similar profiles in managing their microservices architecture.
Our solution would make managing the deployment of multiple microservices easier by applying a single, reusable, pipeline to each of the user's services. It would require minimal configuration by providing sensible default settings that meet the typical demands of a CI/CD pipeline. However, it would still accommodate different CI/CD workflows (varying branching, merging, and auto-deployment strategies).
Furthermore, unlike most commercial products, our solution would be open-source and fully self-hosted, allowing for complete control of code and data ownership. Lastly, it would provide options for testing and inspecting microservices at different levels of granularity.
Seamless
1. Introducing Seamless
Seamless is an open-source CI/CD pipeline tool designed specifically for containerized microservices deployed to AWS Elastic Container Service (ECS) Fargate. It offers a user-friendly interface that is similar to many of the popular interfaces found in commercial solutions. Unlike other CI/CD pipelines, Seamless does not require user-defined scripting through a YAML file template for configuration. Instead, Seamless relies on a core set of default stages: Prepare, Code Quality, Unit Test, Build, Integration Test, Deploy to Staging, and Deploy to Production. This approach makes Seamless easy to use right out of the box. Through the interface, users simply provide the necessary commands needed to run each stage. In the following sections, we will explore the steps a user takes to install, set up, and run Seamless’s CI/CD pipeline on their microservices.
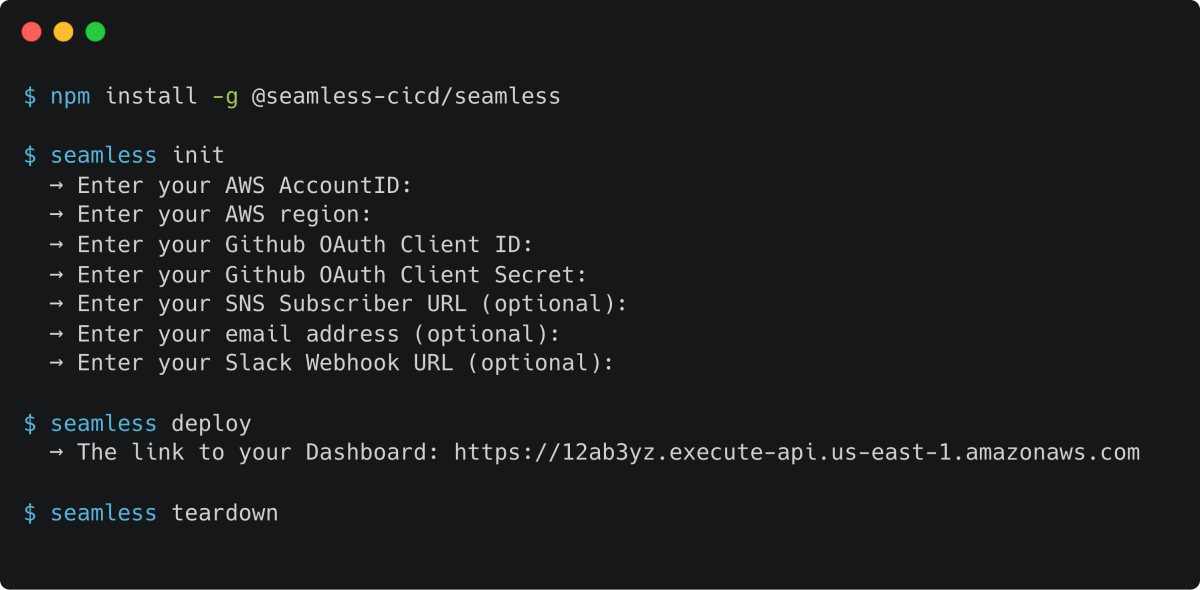
1.1 Installing Seamless
In order to install and deploy Seamless a user must have:
- An AWS account
- The AWS CLI installed and configured
- The AWS CDK command line tool installed
npminstalled
To install the Seamless CLI, the user runs npm install -g @seamless-cicd/seamless. Global installation is required. Next, running seamless init will guide this person through a series of inputs needed to deploy Seamless. After completing the initialization process, executing seamless deploy will provision Seamless's infrastructure on AWS and provide a URL to access the platform's dashboard.
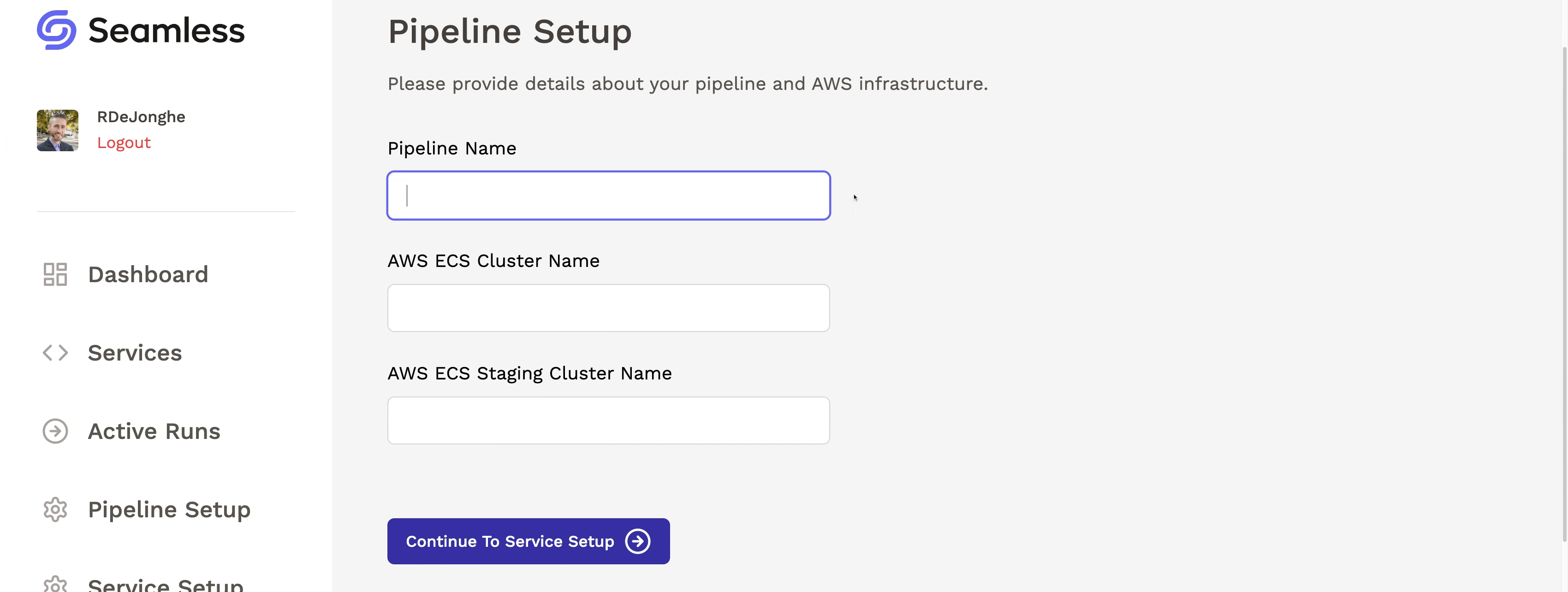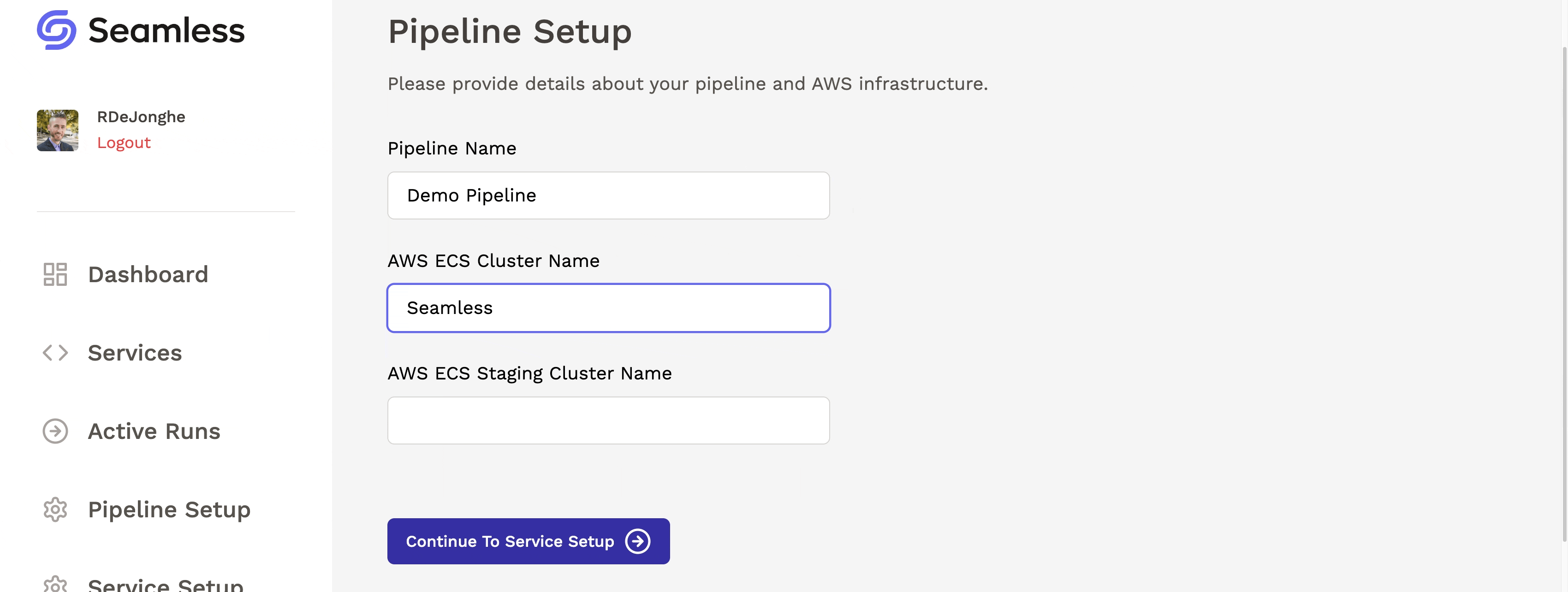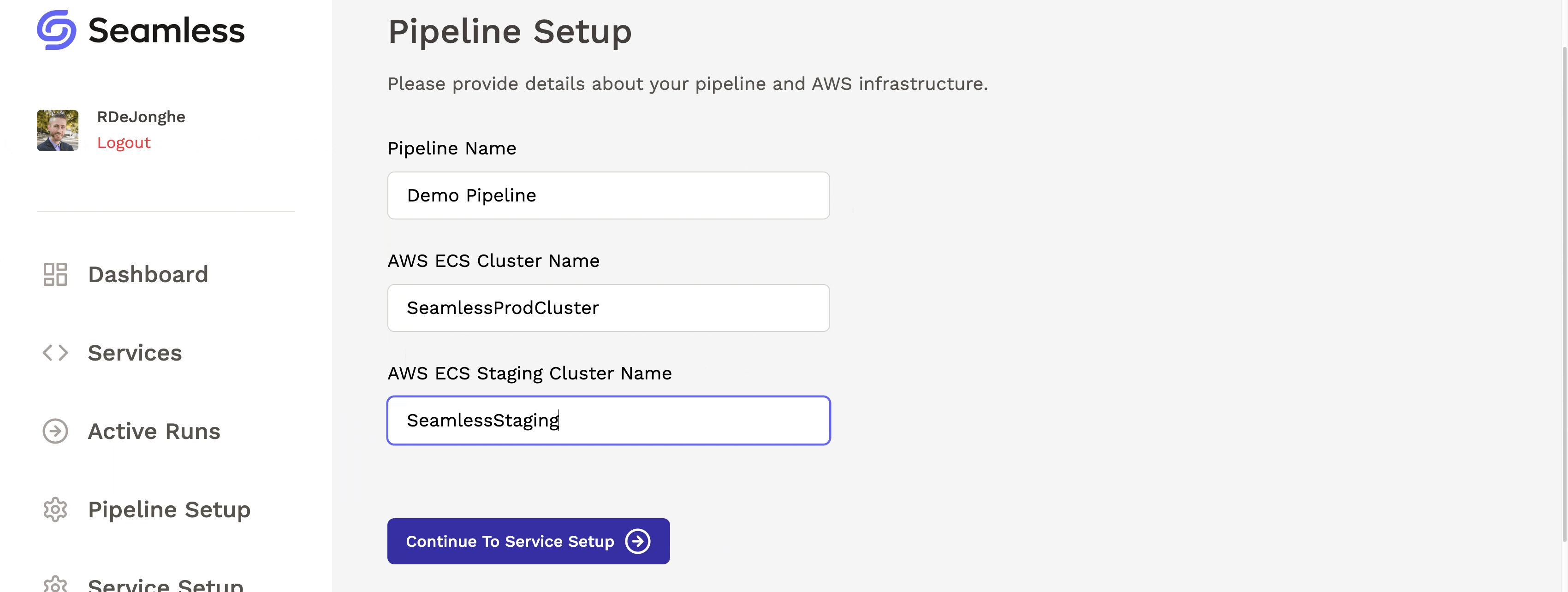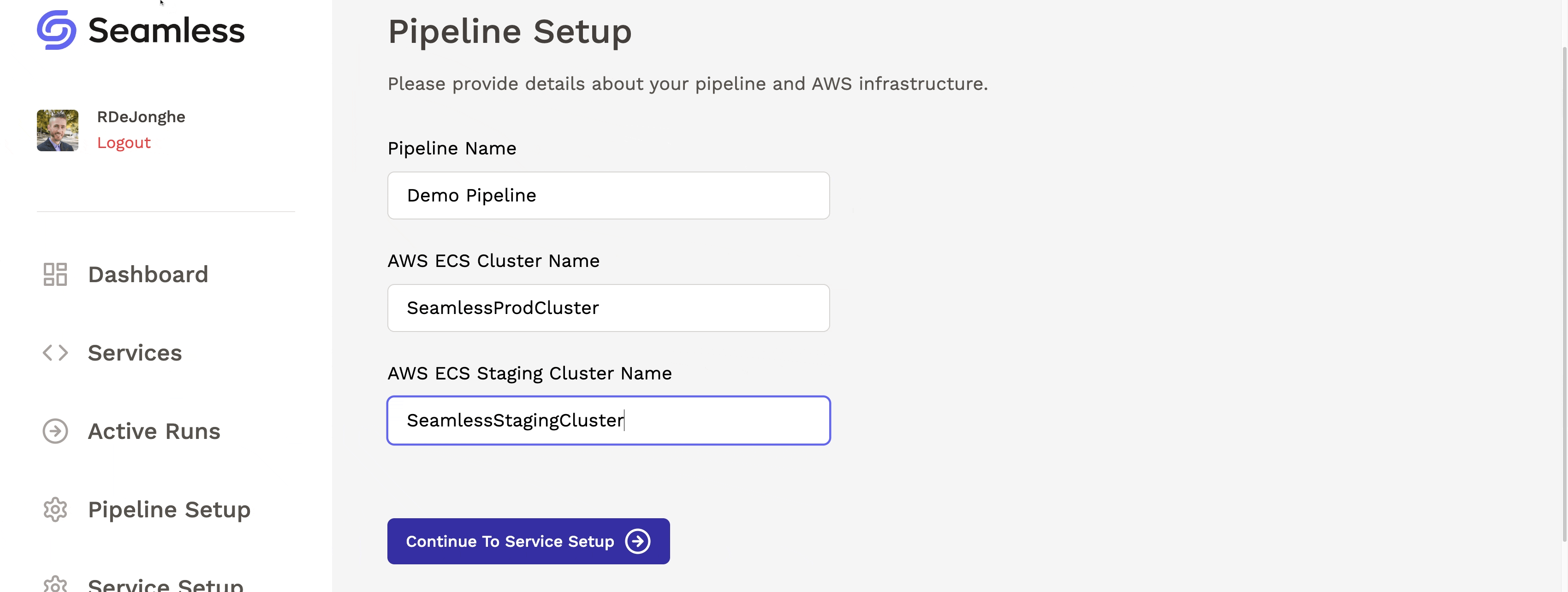
1.2 Using Seamless
After deploying Seamless’s infrastructure, the user can visit the dashboard and complete the pipeline setup process. They will provide the names of their production and staging environments (ECS clusters) so that Seamless knows where to deploy their microservices.
1.3 Connecting Services to the Pipeline
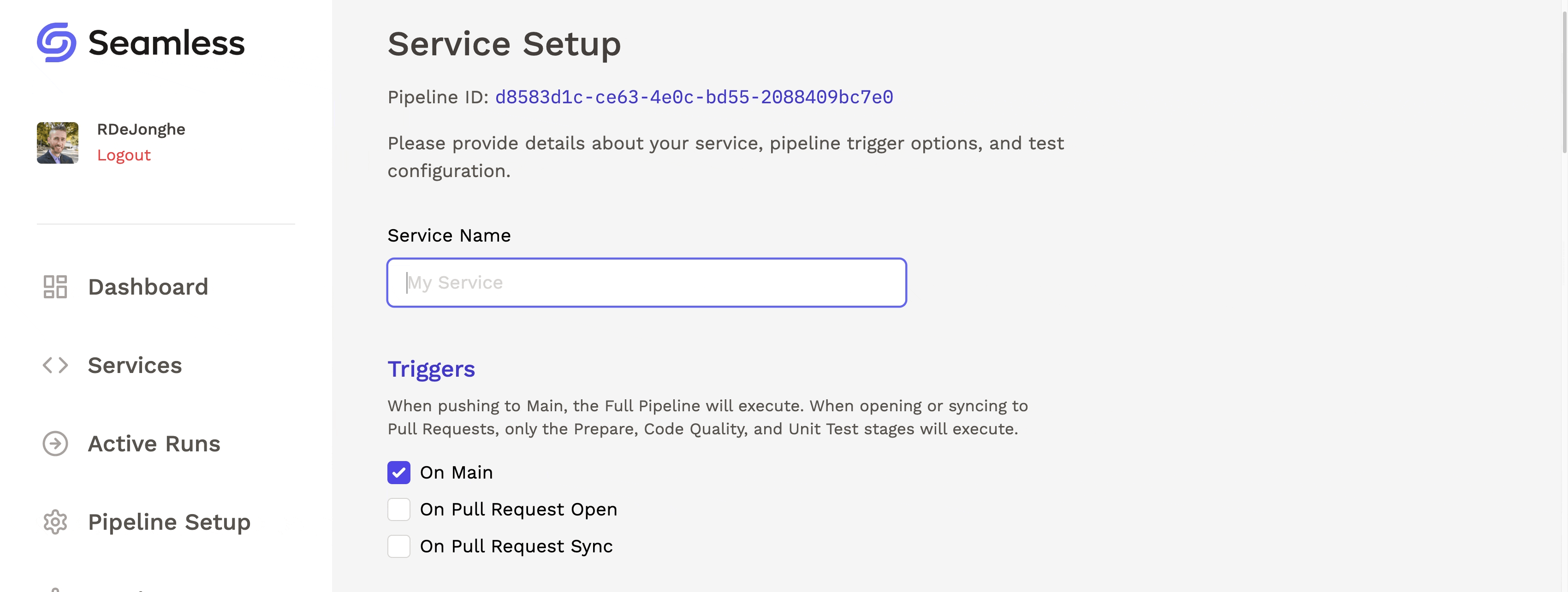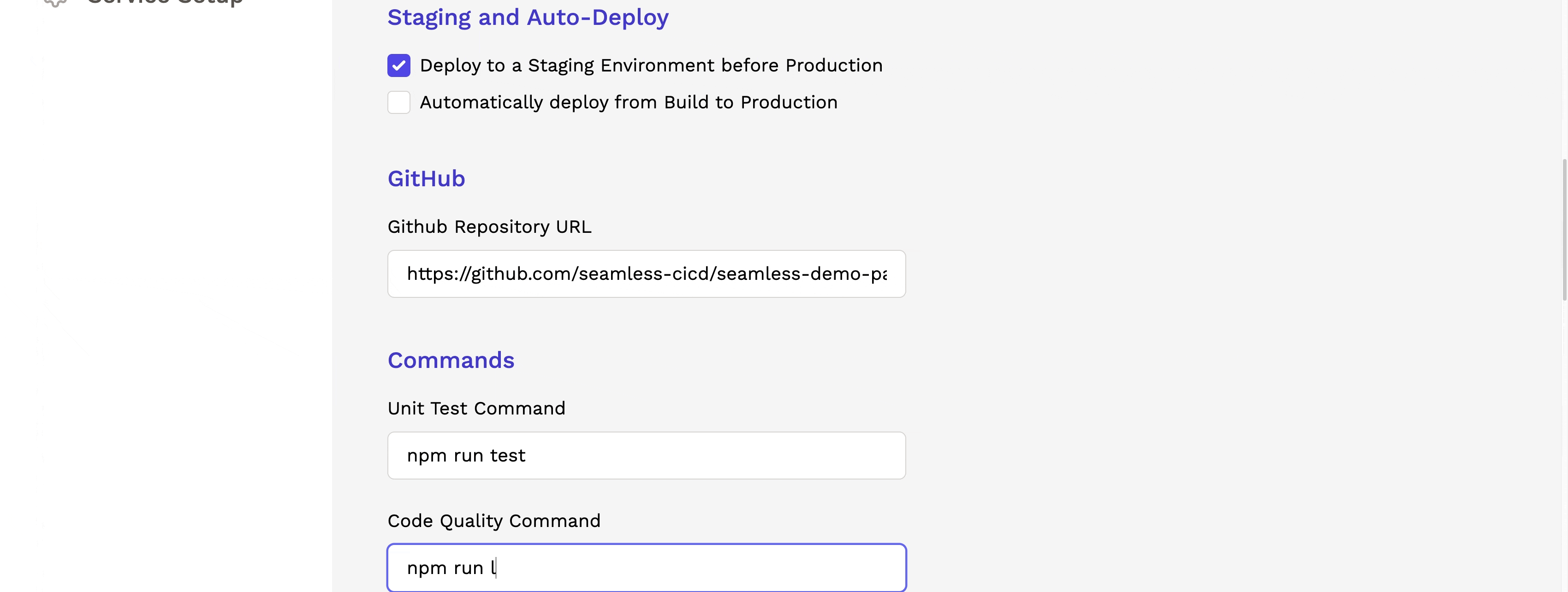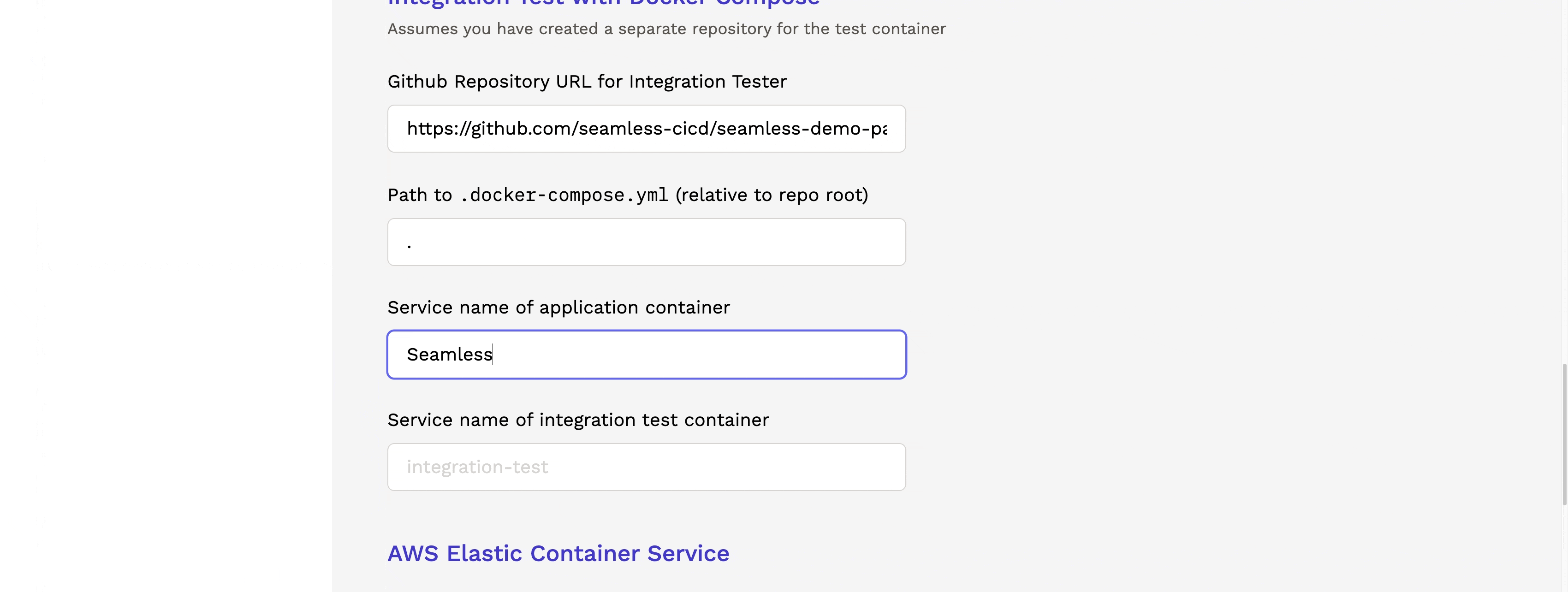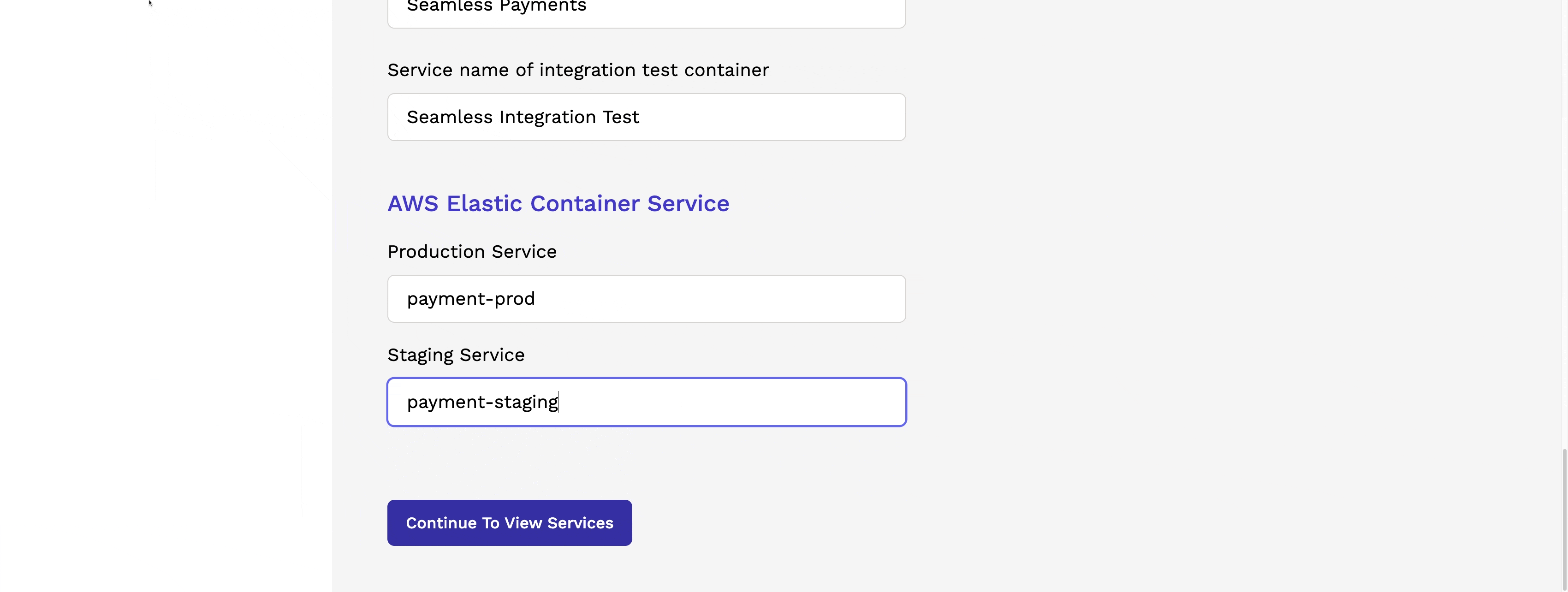
Upon completing the setup of the pipeline, the user can create multiple services that will utilize the pipeline. The service setup process collects all the necessary information to run the pipeline, verify code functionality, and promote it to production.
1.4 Running the Pipeline
Now the pipeline is ready to be activated. It can be triggered manually or by the version control changes:
- A pull request is opened (PR Open)
- A commit is made on a pull request (PR Sync)
- A pull request is merged (Commit to Main)
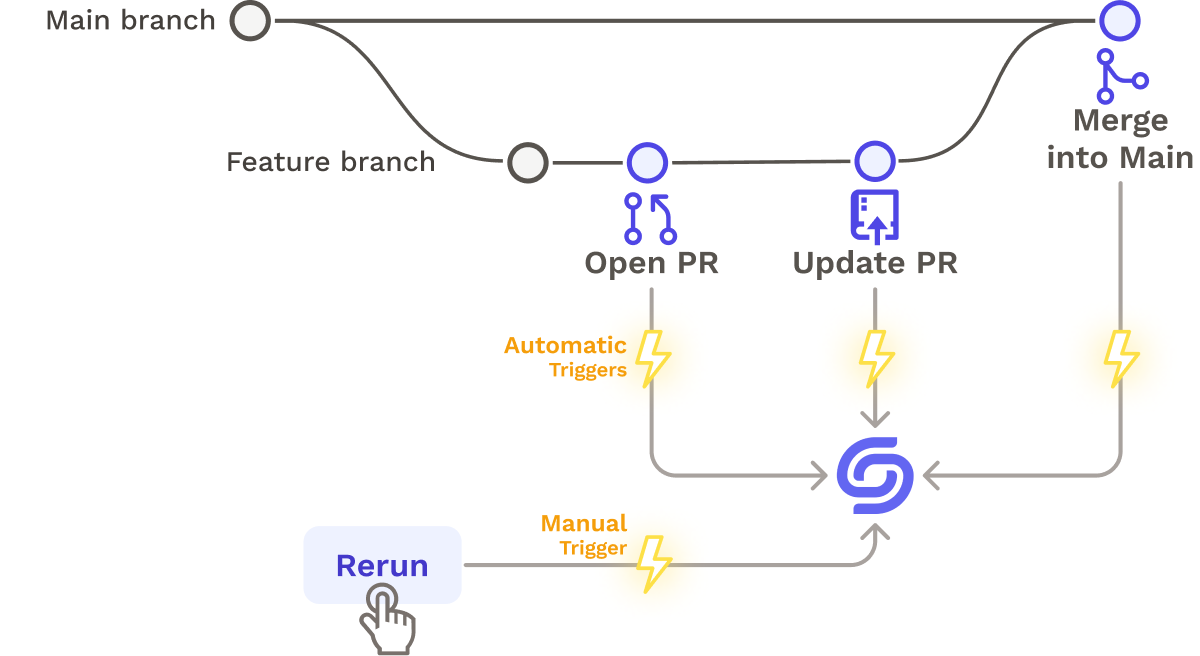
Now that the pipeline is running, the user might want to view its progress.
1.5 Monitoring the Pipeline
Seamless’s UI displays live updates of both runs and stages, enabling users to stay informed of pipeline outcomes as runs and stages transition from “Idle” to “In Progress”, and ultimately to “Success” or “Failure”. Log data is updated live, making it easier to identify and troubleshoot errors when they occur.

We will now shift the discussion toward the technical challenges we faced when building Seamless.
2. Architecture Overview
We’ll start with the fundamental challenges we had to address, provide a high-level overview of our core architecture, and then dive deeper into design decisions and tradeoffs.
2.1 Fundamental Challenges
When building our initial prototype, we focused on the fundamental problems that needed to be solved in order to build the core functionality of a CI/CD pipeline:
- Deciding how to model pipeline data, and selecting a database that we could run detailed queries on
- Configuring code repositories to notify Seamless whenever code changes, and setting up a way to use those notifications as triggers to automatically start the pipeline
- Finding a mechanism to monitor and control the pipeline’s execution flow, with the ability to store complex state
- Determining how and where to execute the physical steps of each pipeline stage
2.2 Core Architecture
After some initial prototyping, we arrived at the architecture below, which shows the high-level flow of how a pipeline is triggered and executed. A backend server listens for webhooks from a code repository, retrieves pipeline information from a database, and starts the pipeline. The pipeline performs a series of tasks, including deploying the updated application to production.
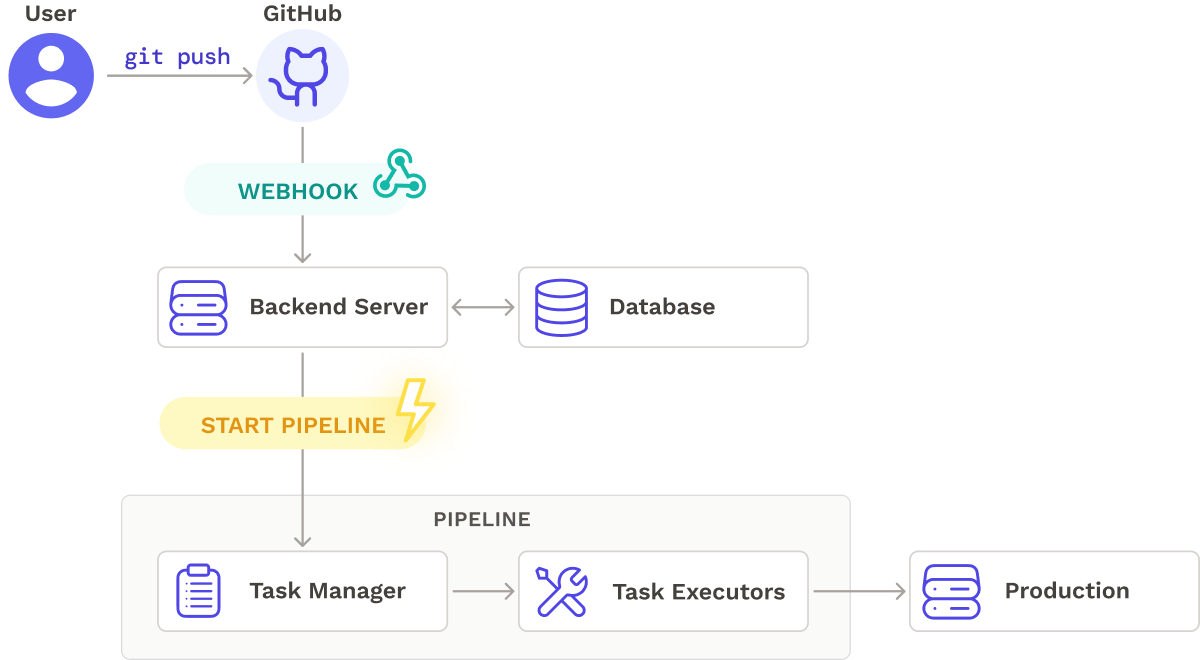
With an overall direction in mind, we decided to explore different options for each component of our core architecture.
3. Building the Core Pipeline Functionality
3.1 Modeling and Storing Data
At the outset, we created a data model that served as the bedrock for the remainder of our application. It comprises four fundamental entities: Pipelines, Services, Runs, and Stages. As a reminder, smaller companies without dedicated teams for managing multiple disparate CI/CD pipelines can simplify their CI/CD management by using a single pipeline for multiple services. Subsequently, our data model establishes a one-to-many relationship between Pipelines and Services. Additionally, each Service can have many Runs and each Run can have many Stages.
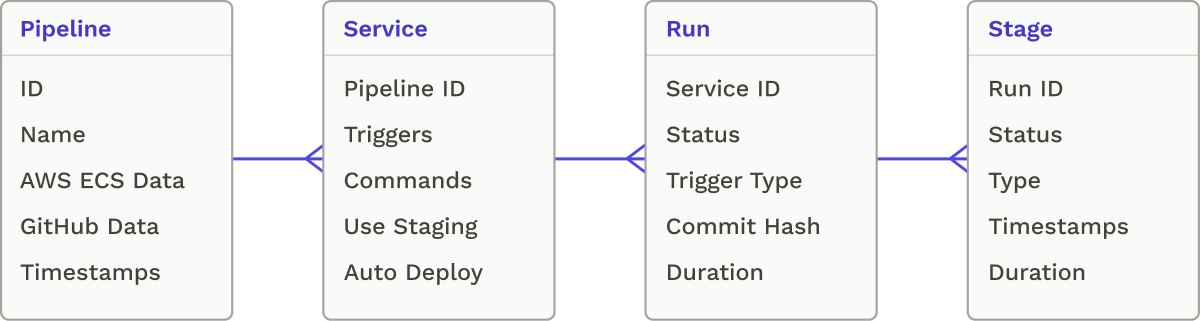
At first, we considered using a NoSQL document store like DynamoDB to store our data. NoSQL document stores are optimized for speed, scalability, and storing unstructured data. However, given that our project does not involve high-frequency read or write operations, and our schema is fixed, we opted for PostgreSQL, a relational database. We rely on the Prisma ORM to streamline schema creation and migration, as well as data manipulation.
With our data model in place, we narrowed in on how we could automate the journey of code from source to production.
3.2 Automating Pipeline Runs
A key component of automated deployment pipelines is their ability to execute immediately when source code is modified. Webhooks are used to link user repositories to the pipeline:
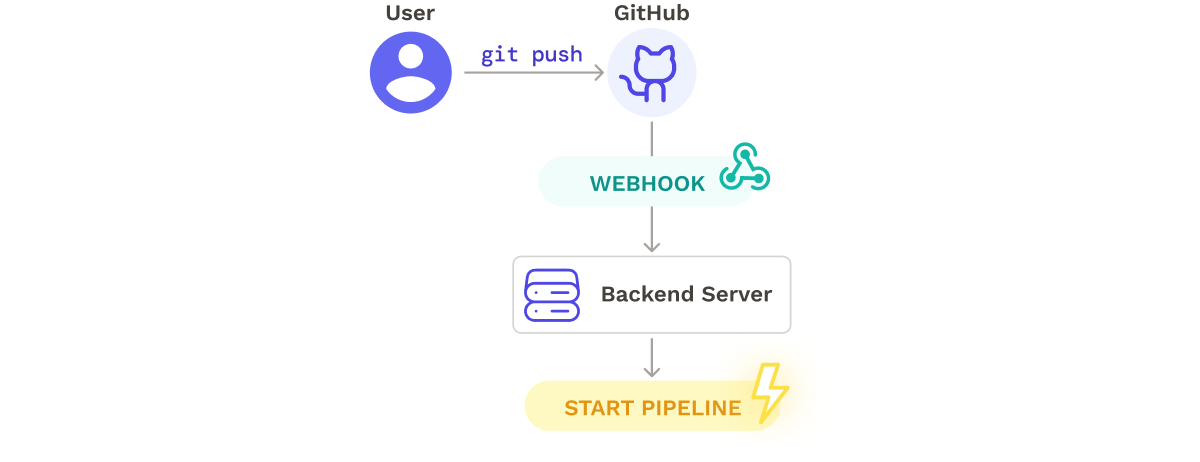
Seamless registers the webhooks using Github’s Octokit client. The flow from Webhook registration to pipeline initiation is as follows:
- Seamless creates a webhook in the user's repository, utilizing GitHub's Octokit client to authenticate and interact with their API.
- The user makes an update to the source code.
- GitHub sends a webhook to Seamless’s backend server.
- The backend uses the payload of the webhook to identify the trigger and initiate the appropriate pipeline process.
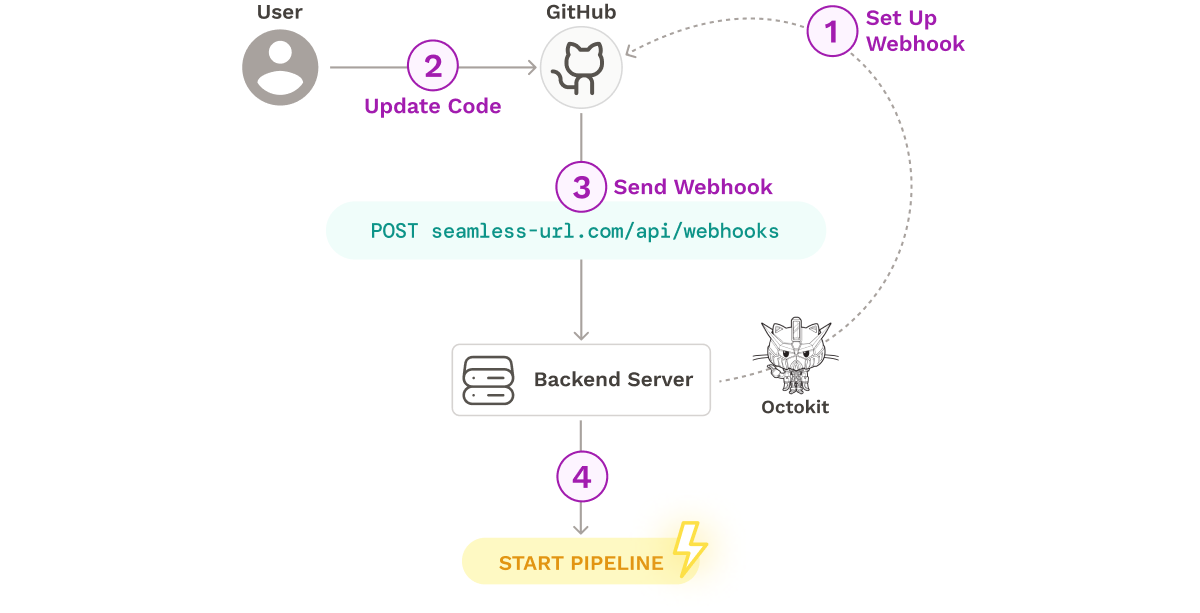
However, running the entire deployment pipeline for every change would have compromised our goal of velocity. To overcome this challenge, we tailored our pipeline to three distinct triggers:
- Merge/Push to Main
- Open Pull Request
- Synchronize/Update Pull Request
For pushes to the main branch, the entire pipeline is executed, whereas pull request opens and synchronizations only perform code quality checks and tests, without any intention of deployment:

With a system in place to trigger the pipeline, we moved on to building out the pipeline itself.
3.3 Managing Pipeline Execution
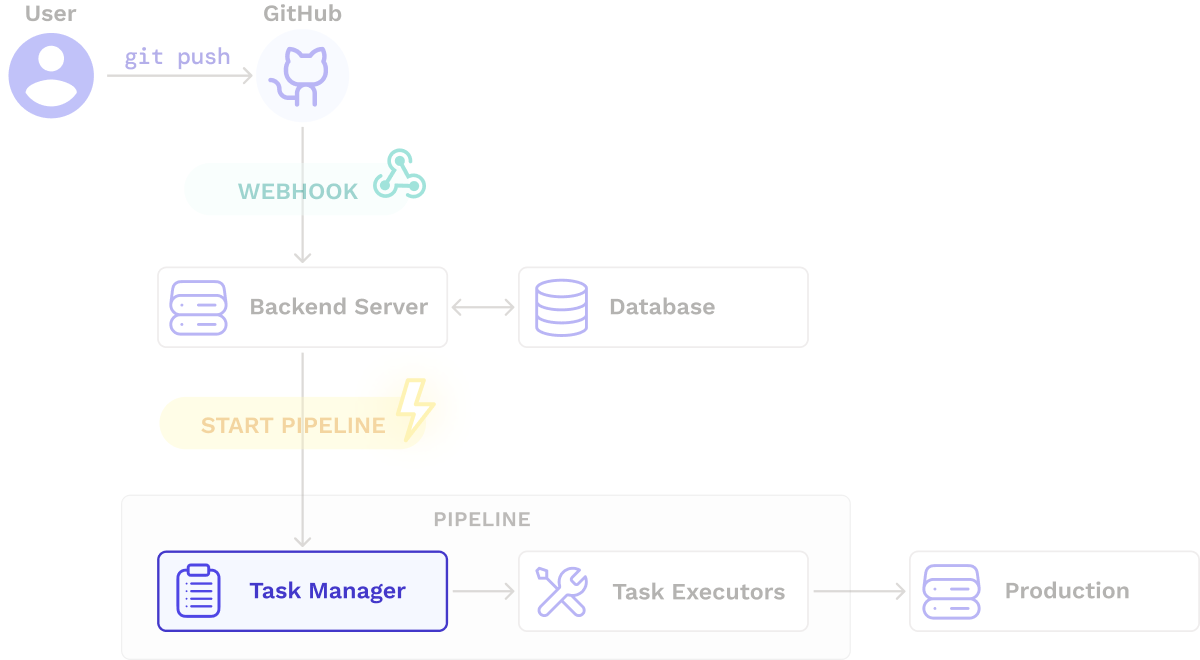
First, we needed to consider how to manage the execution flow of our pipeline. We aimed to avoid having a single fixed execution path for our pipeline, as the degree to which different companies' CI/CD workflows embrace automation can vary significantly. The execution path could differ depending on:
- What triggered it
- User-configured settings, such as whether a staging environment is used
- The success of tasks
We wanted to build a system that would behave differently depending on these factors. We also wanted our system to keep track of the state of the pipeline as it ran so we could inform users of it.
Our initial approach to managing tasks was to use a job queue to run tasks in a linear manner. This did not suffice for our final use case. The job queue lacked built-in capabilities to model nonlinear execution paths taken by our pipeline. Furthermore, it did not provide a centralized way to track the status of the pipeline and its stages, nor could it guarantee that only one stage was executing at a time.
We also looked into event-driven architecture where each task would call the next, and there would be no manager. However, we felt that having a central place to manage state would make managing and debugging our pipeline easier.
Ultimately, we decided to use a state machine to orchestrate pipeline executions. The state machine model allowed us to describe the behavior of our pipeline by defining all possible states for each stage (such as Idle, Success, Fail, or In Progress), the transitions between these states, and the decisions along the way that could affect its execution flow.
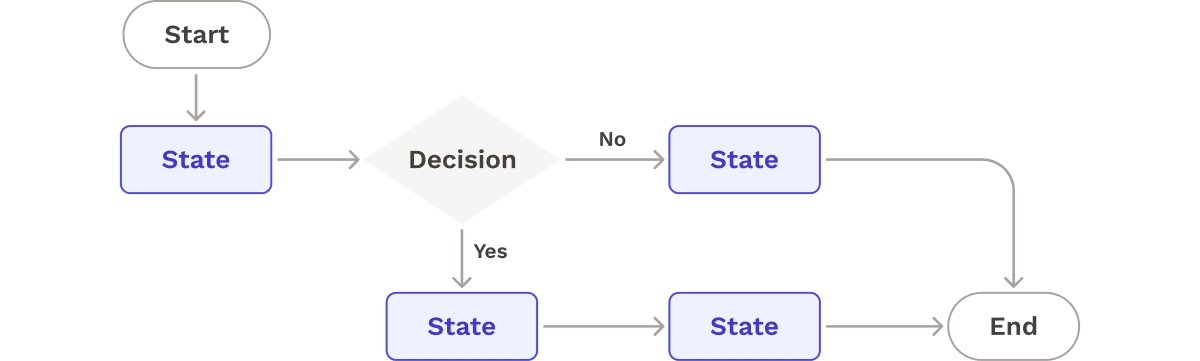
One drawback to state machines was that defining states and transitions in advance would limit the ability to add new steps dynamically. As a result, the core logic of the pipeline would be unmodifiable once it is set up. We determined that this tradeoff was acceptable for our use case. Smaller organizations early in their adoption of microservices are more likely to have services with similar CI/CD requirements, resulting in a reduced need for customizability.
Next, we needed to determine how we would run our state machine. We knew the state machine would have varying usage patterns, depending on the team's commit rate and other factors. To accommodate this flexibility, we opted for a serverless, pay-as-you-go infrastructure that could scale according to our users' needs.
AWS offers a serverless state machine service called Step Functions that integrates natively with other AWS services. As the Step Function progresses through the stages in our pipeline, it uses a context object to communicate pipeline status to our backend effectively.
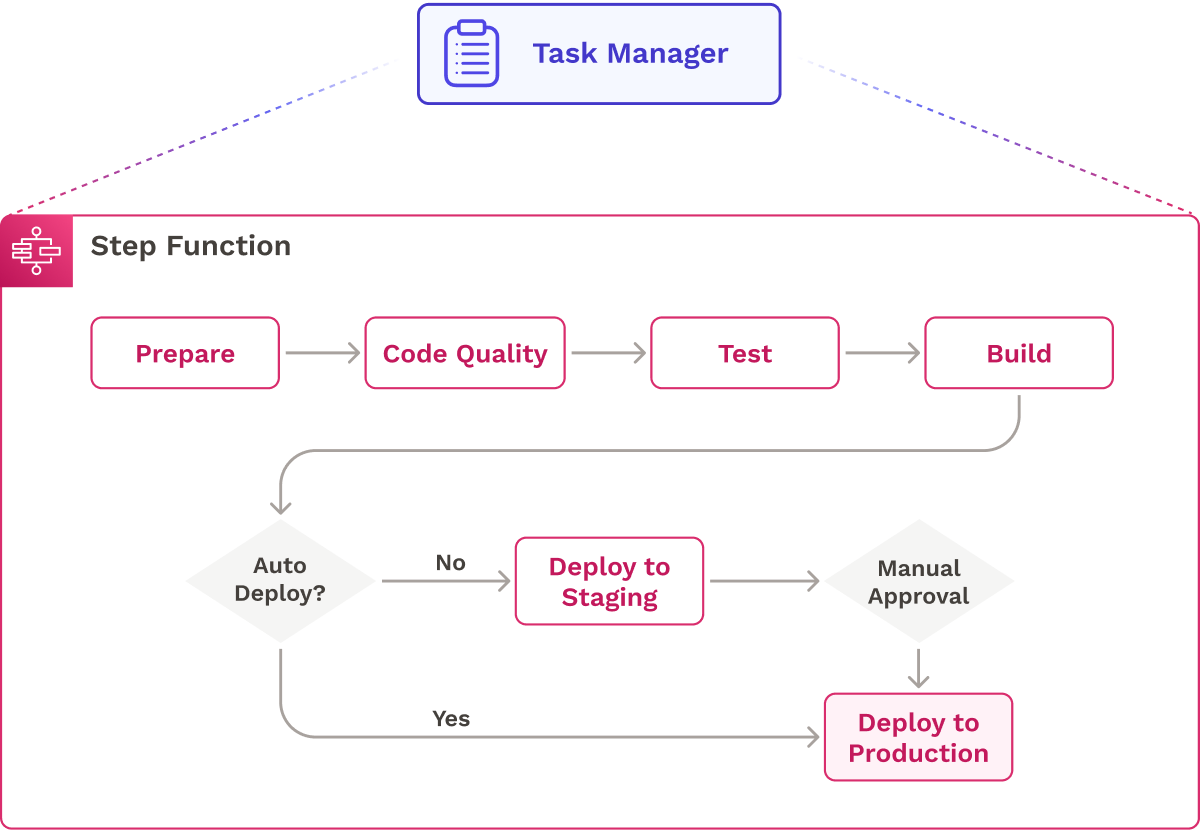
We also considered running the state machine directly on our backend servers, utilizing the XState JavaScript library to define the logic, but its lack of AWS integrations made it less suitable for our needs. Additionally, this approach may have introduced scaling challenges that were abstracted by using step functions.
At this point, we had a tool that would help us manage pipeline tasks, but we also needed to consider how to run the tasks themselves.
3.4 Running Tasks
A pipeline task comprises the set of operations that must be performed to fulfill the purpose of a given stage. In Seamless, a task is a Javascript program. Some of these programs run child processes that execute commands for cloning, building, and testing code, while others use the AWS SDK to perform deployment-related actions.

Now that we know what a task is, let’s look at the two infrastructure choices we had for running these tasks: virtual machines and containers.
3.5 Virtual Machines or Containers
To determine the appropriate infrastructure for running pipeline tasks, we examined the nature of the tasks themselves.
- Tasks are consistent: For every pipeline run, each task should operate in the same way.
- Tasks are ephemeral: Once a task runs, it will not rerun until the next pipeline execution.
- Tasks fluctuate with demand: Depending on the team's commit rate and other factors, the frequency at which a task runs can vary over time.
One approach we explored was having a dedicated build server running on a virtual machine (VM) to build, test, and deploy a user’s application. This fulfilled our need for a centralized, consistent environment to run tasks. Additionally, VMs also offer full hardware virtualization, providing strong isolation from other virtual machines running on the same host. However, the virtual machine approach had a few drawbacks:
- Elasticity: Scaling VMs to meet the demands of the pipeline is slow because they take a few minutes to start.
- Resource-Intensive: VMs require significant resources since each virtualizes an entire operating system. Furthermore, the VM running the pipeline would need to be configured with all dependencies to run any pipeline tasks.
To overcome the limitations of virtual machines, we explored alternative solutions and discovered that using containers to run steps in CI/CD pipelines is a prevalent industry trend.25 Like a build server on a virtual machine, containers provide consistent environments for running tasks. However, unlike virtual machines, containers are more lightweight, meaning that they can more easily spin up and down automatically to match demand.
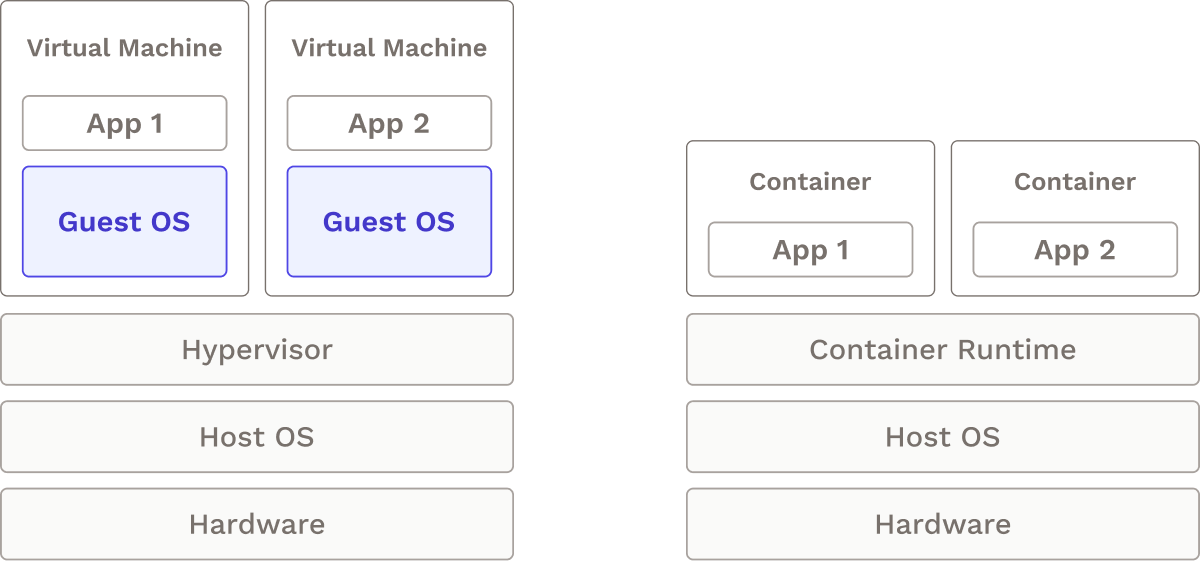
As our infrastructure was already hosted on AWS, we aimed to find an AWS-native way to run containers, and so decided to use Amazon’s Elastic Container Service (ECS).
3.6 Managing Servers
Our next decision was whether to run containers in a serverless fashion with ECS Fargate or to have direct access to the virtual machines hosting the containers. While Fargate would reduce underlying server management overhead, it was not a feasible choice. We actually needed access to the underlying virtual machines in order to run Docker within our containers for tasks such as building services as images. Without access to the virtual machines, we couldn't achieve this functionality. Consequently, we determined that running ECS on EC2, AWS’s virtual machine service, was the optimal solution for our specific requirements.
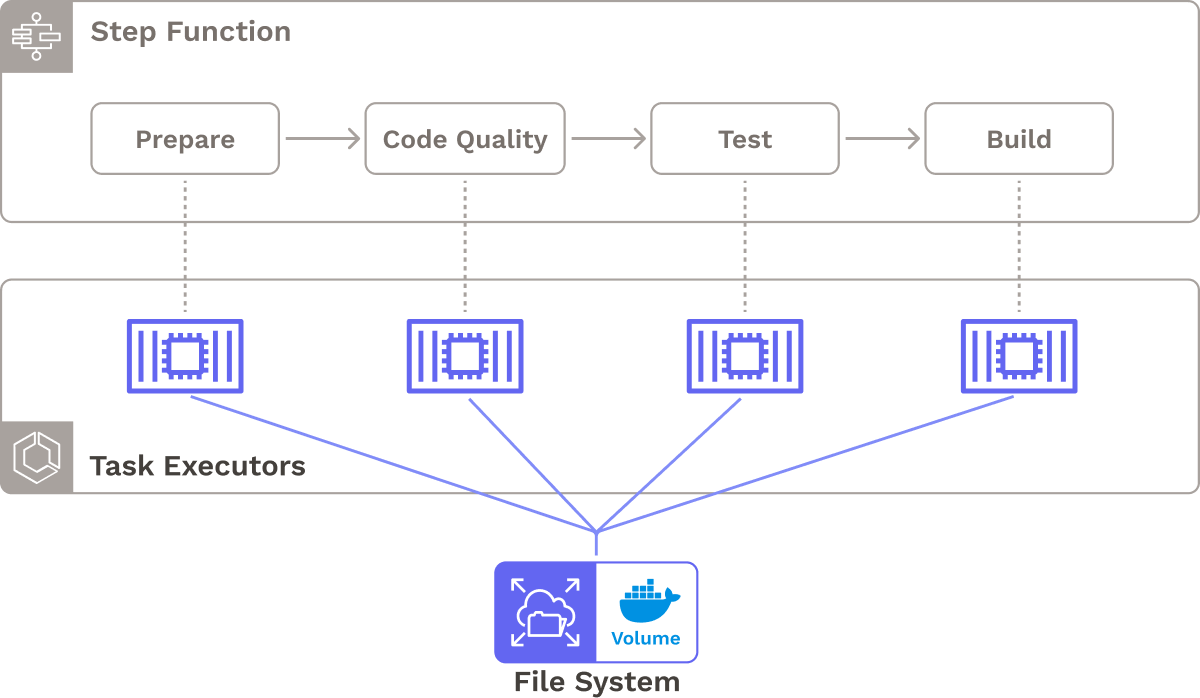
Since Step Functions natively integrates with other AWS services, we could trigger the ECS task containers (or, as we call them, Task Executors) directly from it, as the below diagram depicts:
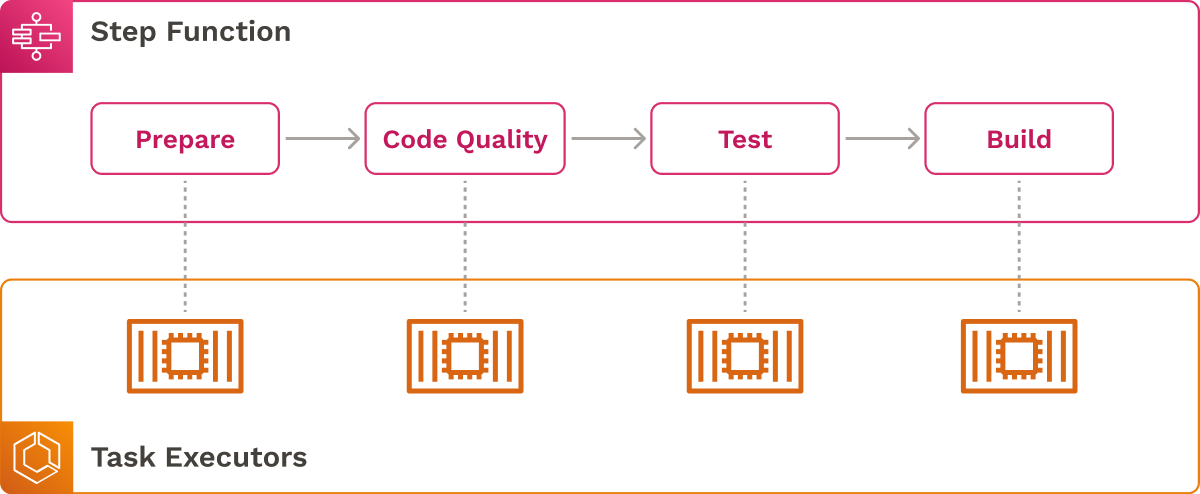
3.7 Overview of Core Functionality
Ultimately we settled on the following implementation for our core architecture:
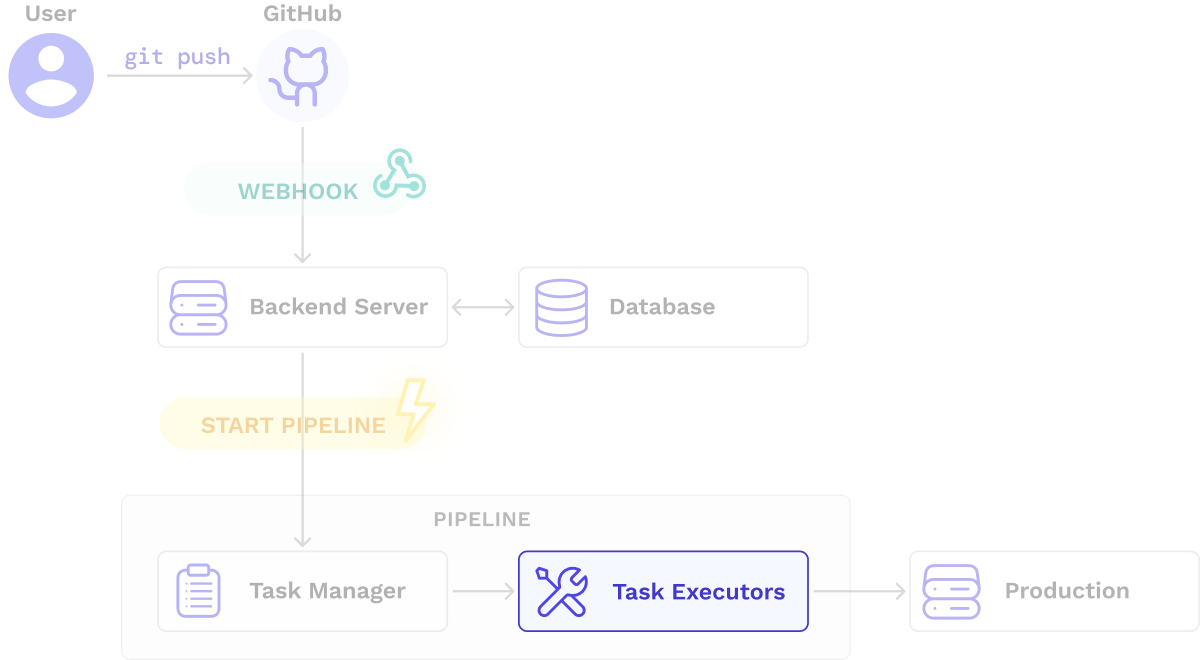
- A change in the user’s Github repository sends a webhook to Seamless’s backend.
- Seamless’s backend processes the webhook and fetches relevant information from Postgres to start the state machine.
- A state machine running on Step Functions orchestrates the pipeline execution flow.
- The state machine calls ECS task executors to run pipeline tasks.
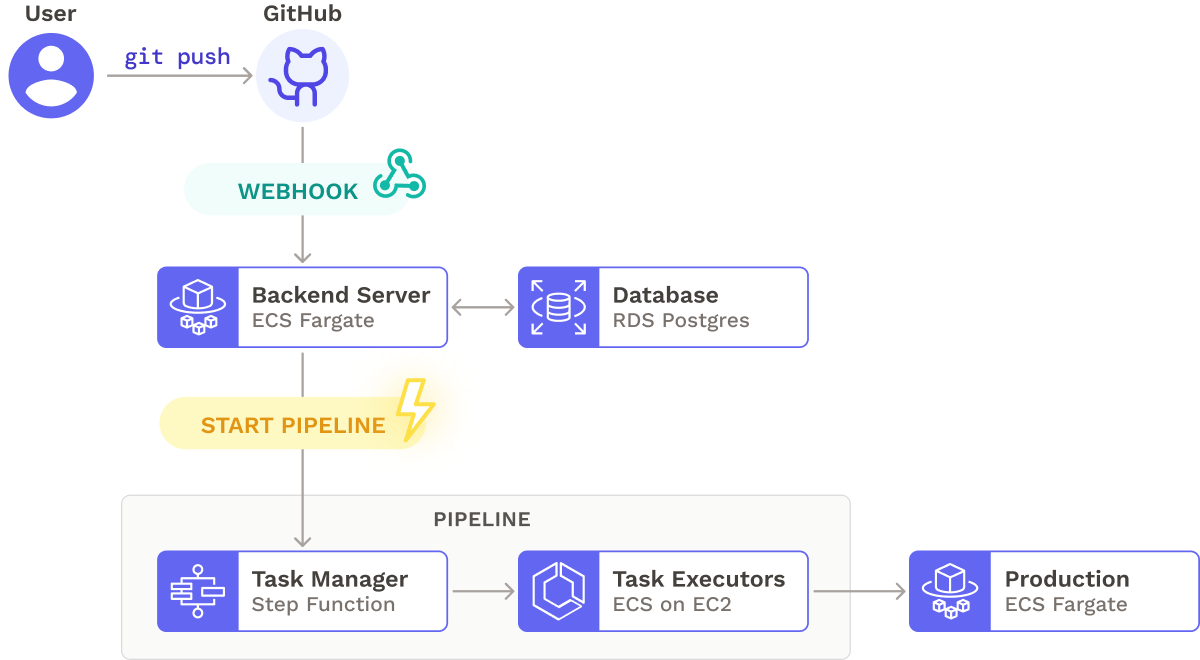
Once we had built the structural foundation for the pipeline, we looked to expand our project further.
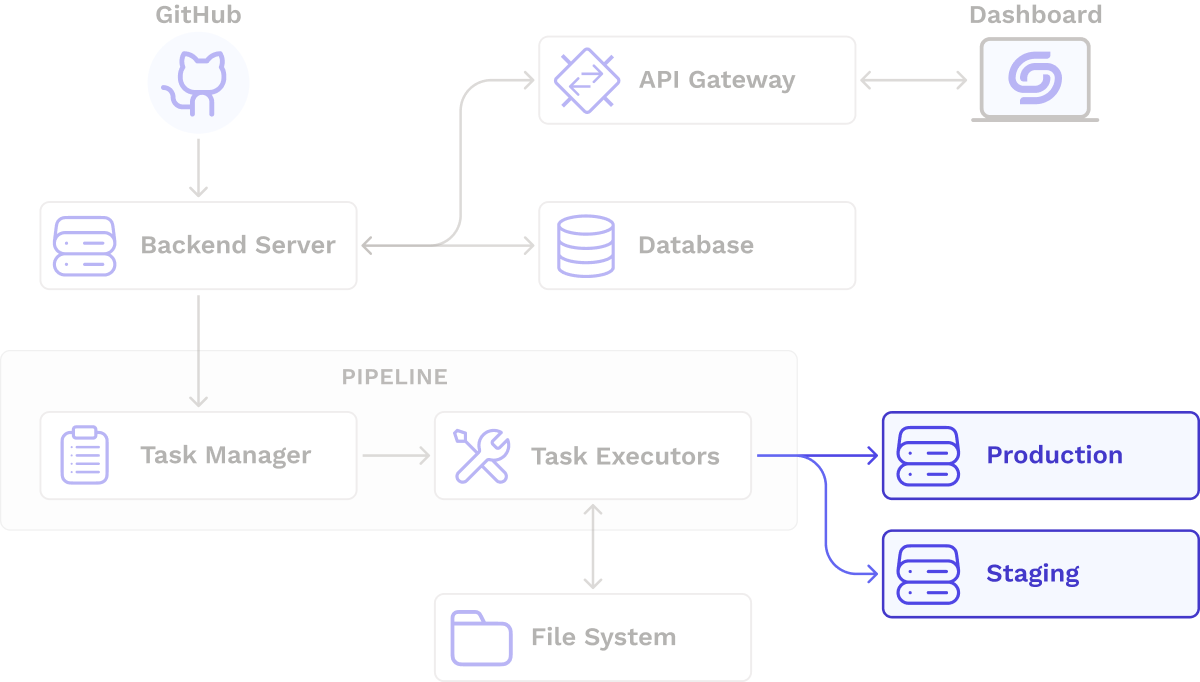
4. Improving Core Functionality
Once Seamless’ core functionality was working, users were able to automatically test, build, and deploy their microservices upon changes in version control. With our core pipeline in place, we decided to add features to make our CI/CD pipeline more robust and targeted toward microservices. Below is a more detailed diagram of our architecture, with improved functionality in place:
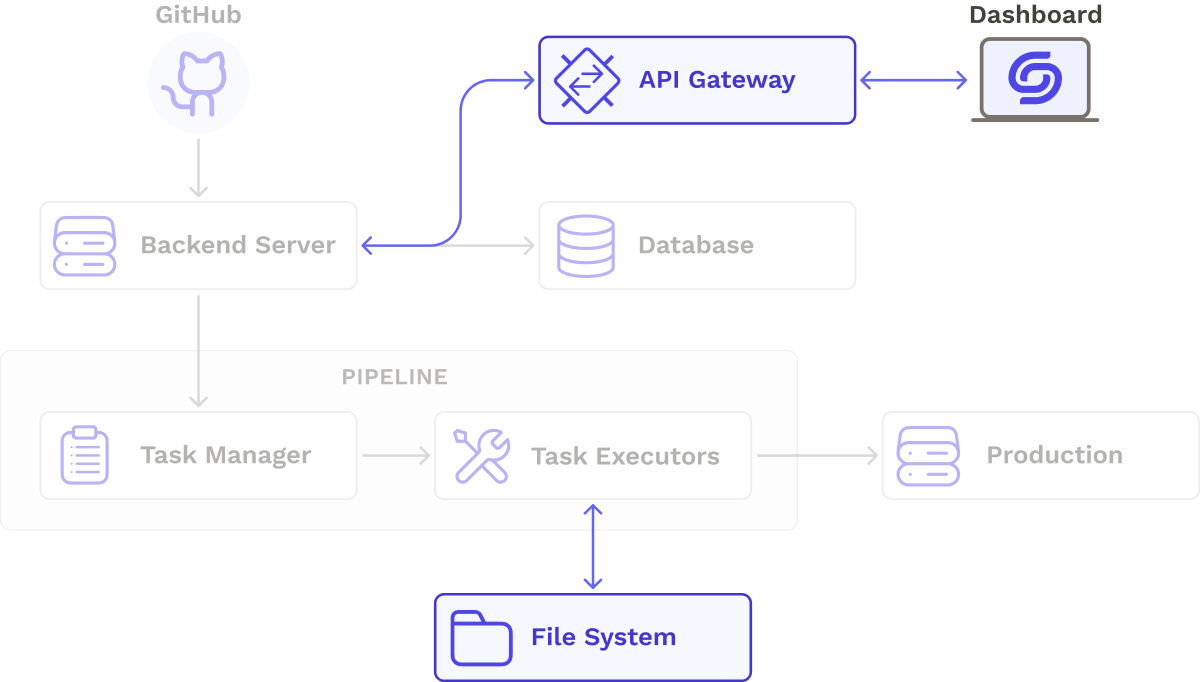
4.1 Realtime Dashboard Updates
In order to give the user the ability to detect and respond to pipeline issues as they occur, we implemented real-time updates that are sent to our dashboard.
We considered using client-side polling, where the client queries the API at regular intervals but ultimately decided against it because it generates unnecessary HTTP requests and might cause delays between backend and frontend updates. We decided to use WebSockets instead. The dashboard initiates a WebSockets connection to a Websockets API Gateway on the backend. Status updates and logs arriving on the backend are forwarded to the dashboard via the WebSockets connection persisted by the API Gateway.
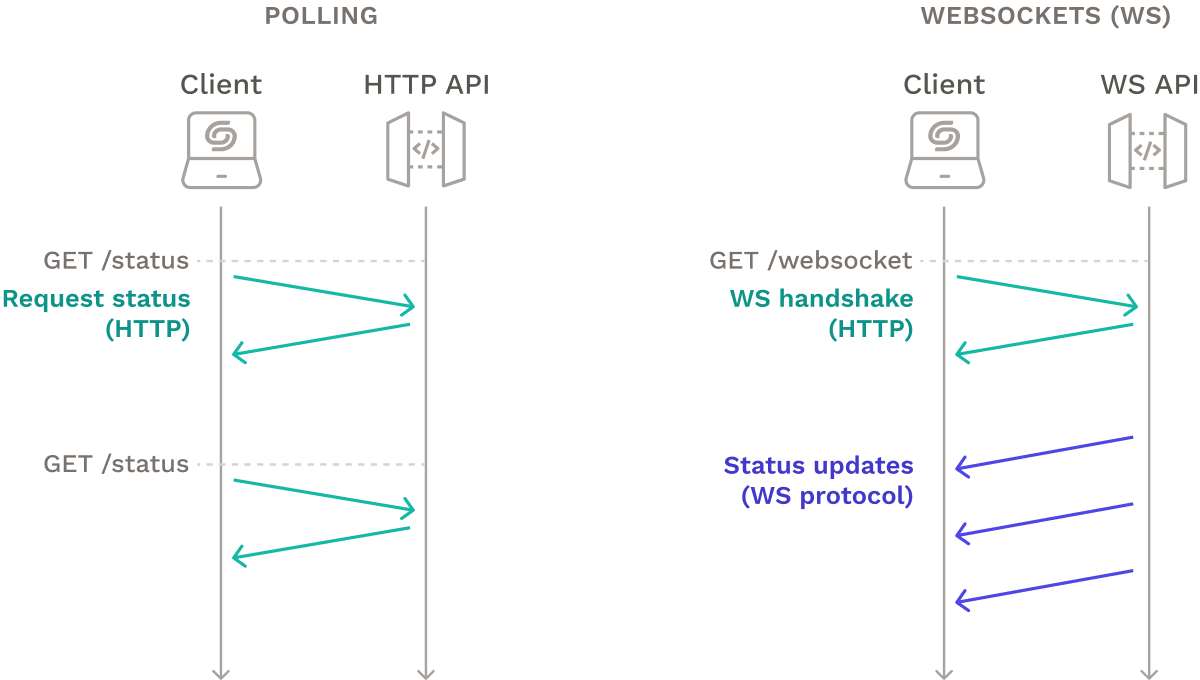
4.2 Improvements to Pre-Deployment Tasks
Sharing Data Among Containers
To minimize repeated work, we needed to ensure that multiple pipeline tasks could access the same files. For example, the Prepare Stage clones the source code so the Build Stage can package it into a Docker image later. To achieve this, we used the AWS EFS network file system, which is designed to be mounted to any number of EC2 instances or ECS containers. EFS scales automatically by providing the necessary storage without needing to specify the capacity in advance.
When each container is started, it is automatically mounted to a shared persistent Docker volume on EFS. The hash of the commit that triggered the current execution serves as the directory name for the source code, which prevents naming conflicts and enables pipeline executions from separate commits or services to occur in parallel. If two commits cause two concurrent pipeline executions, the files generated by either execution will not interfere with one another.
We also considered block storage. Although block storage presented some performance advantages, it was designed to be accessed from a singular virtual machine, making it unsatisfactory for our distributed task containers that were running across multiple VMs.
Integration Testing
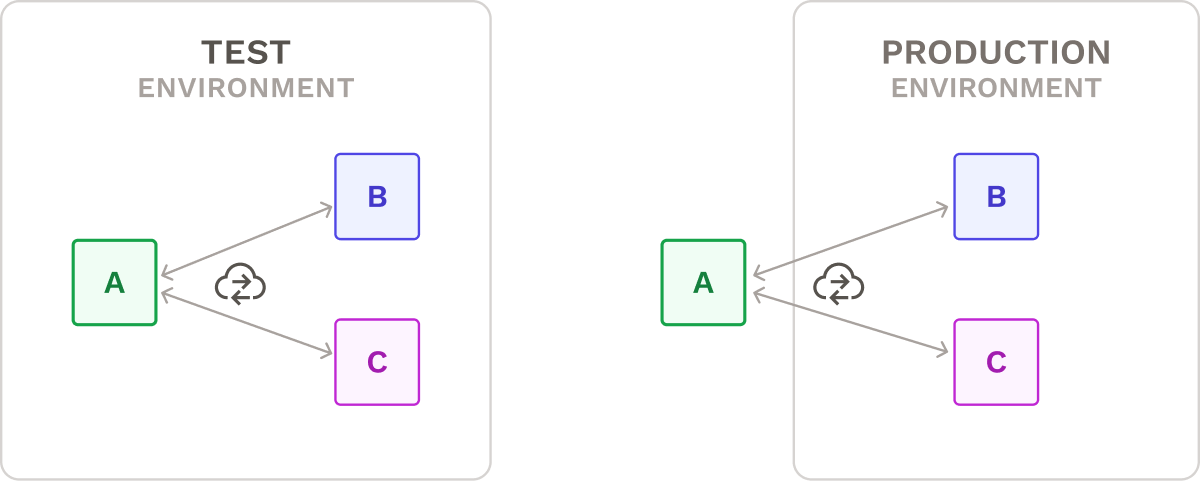
Earlier, we presented integration testing as a key testing strategy for microservice architectures, where multiple microservices are tested together as a whole subsystem. To show an example, let’s examine two methods for performing integration tests for a new version of Service A against the latest versions of Service B and C.
One option is to test the new Service A against live, production instances of Service B and C, but this approach has a major drawback: any destructive calls made during testing could unintentionally alter the production system's state or affect its performance.
Another approach is to spin up instances of Service B and C in an isolated test environment. Despite added complexity and additional resource requirements, this approach avoids the risks of interfering with production instances of services.
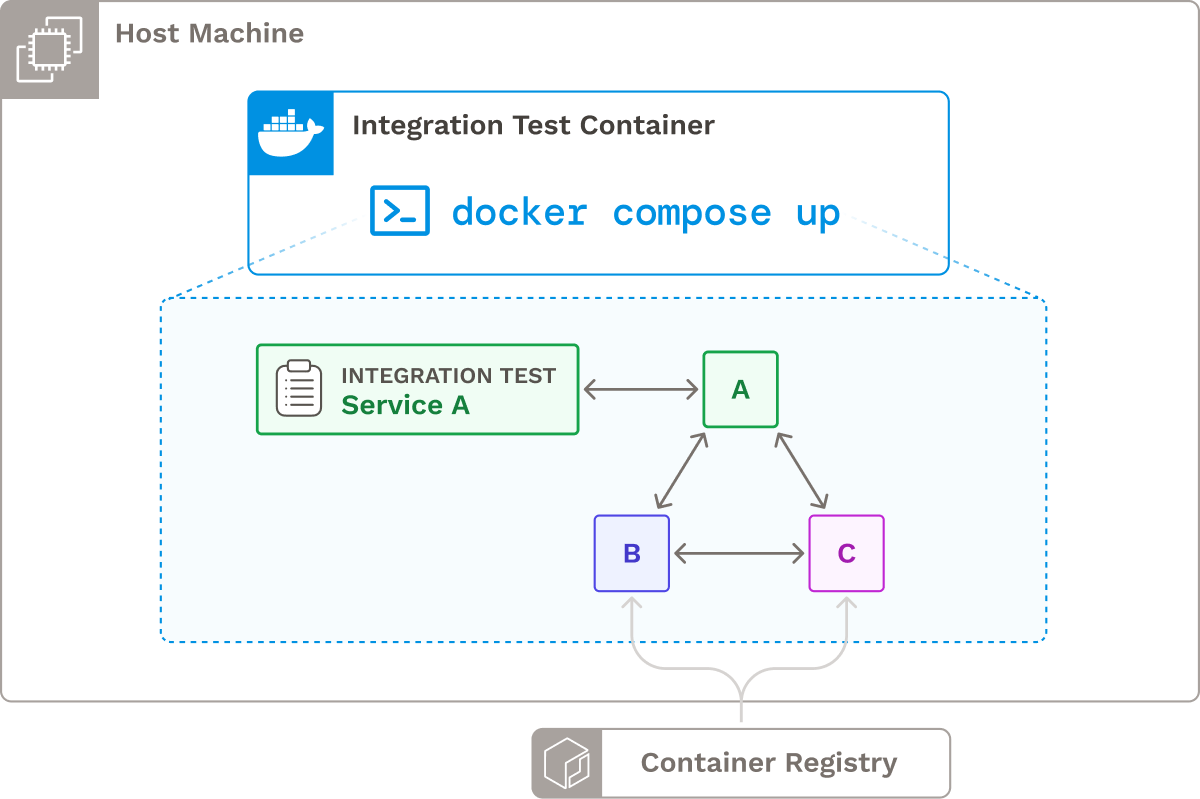
To accomplish this, we leveraged Docker Compose, a service that facilitates container management and networking. The user provides a Docker Compose configuration file that specifies the dependency services required to run integration tests for Service A. During the integration testing phase, Docker Compose pulls the latest versions of the dependency services from a container registry and runs the integration tests.
This approach offers several benefits, including the ability to test in an environment that closely mirrors production and avoiding the risk of inadvertently affecting live data. Moreover, it aligns with the user's existing workflow if they already use Docker Compose for local testing.
So far, we have focused on tasks that occur pre-deployment. Now we will dive into tasks directly related to deploying services.
4.3 Improvements to Deployment-Related Tasks
Manual Approval of Staging Environments
Most of Seamless’s pipeline executes in a fully automated fashion. However, most CI/CD workflows do not embrace full continuous deployment, so Seamless provides an optional staging environment from which the user could manually approve deployment to production.
There were two patterns we could use to link stages to one another:
- Proceed immediately to the next stage after one stage completes
- Pause after a stage completes
AWS Step Functions offers two analogous job invocation styles: “Synchronous” and “Wait for a Callback Token”. The Synchronous model was suitable for most stages because each stage should automatically start after the previous one finishes. However, if the user disables continuous deployment, the state machine should pause so the developer can perform quality checks on the staging environment. This second scenario was a good use case for Step Function’s Wait for a Callback Token pattern.

Even if a staging environment is used, there is still a possibility of faulty code reaching production. For this reason, we decided to implement rollbacks.
Rollbacks
New and small companies often prioritize speedy code releases, which can carry the risk of introducing errors or failures in the production environment. Rollbacks allow teams to restore a previous stable version of a service.
To enable rollbacks, we tag all Docker images with the git commit hash. Our UI displays all possible rollback images, giving users a choice of rollback targets. Instead of redeploying the entire system for a given rollback, each service can be rolled back independently, minimizing the impact on the overall deployment.
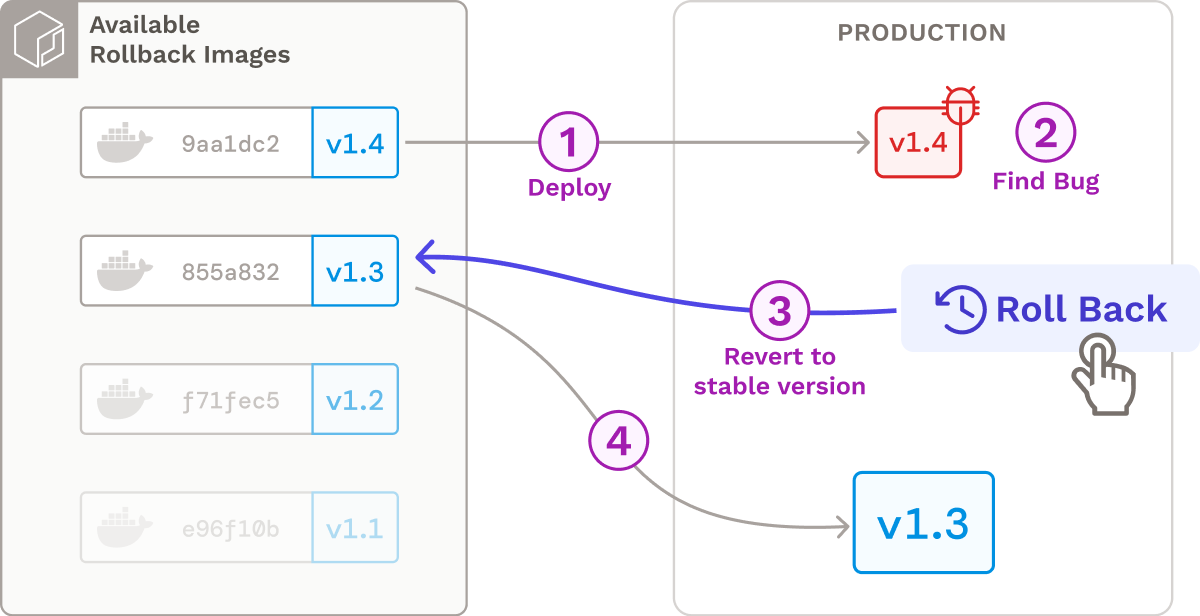
Automatic Deployment of Fargate Clusters
Since Seamless is targeted toward smaller teams that might lack experience deploying microservices, we built a feature that automatically deploys the user’s Docker images to a Fargate Cluster and implements service discovery using AWS Service Connect. This approach helps users get their services up and running in production quickly, as they only need to provide basic information about their service and its image. The feature can be used to set up both staging and production environments.
At this point, our core architecture looked like this:
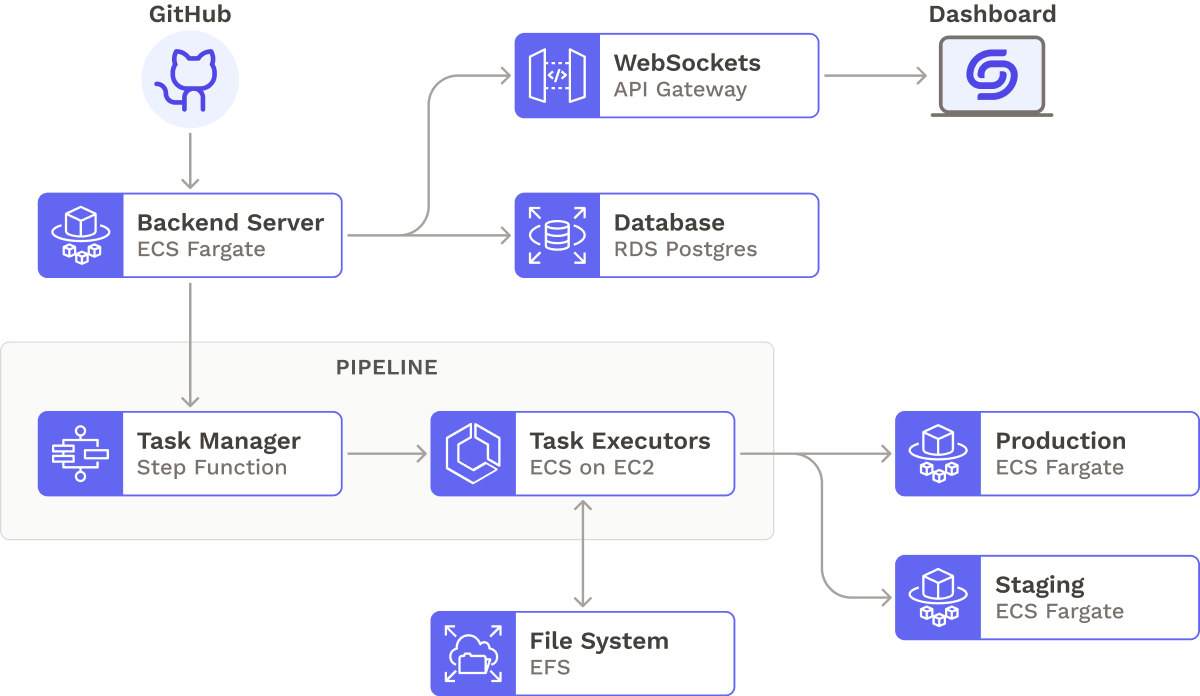
With our core functionality in place, we made Seamless a complete application by considering performance and scalability, security, notifications, and logging.
5. Beyond the Core Pipeline
There were a few additional infrastructural considerations and features remaining for us to review. Infrastructurally, we wanted to make Seamless more performant, scalable, and secure. We also wanted to add features that would make it easier for the user to monitor their pipeline, including notifications and log streaming.
5.1 Designing for Performance and Scale
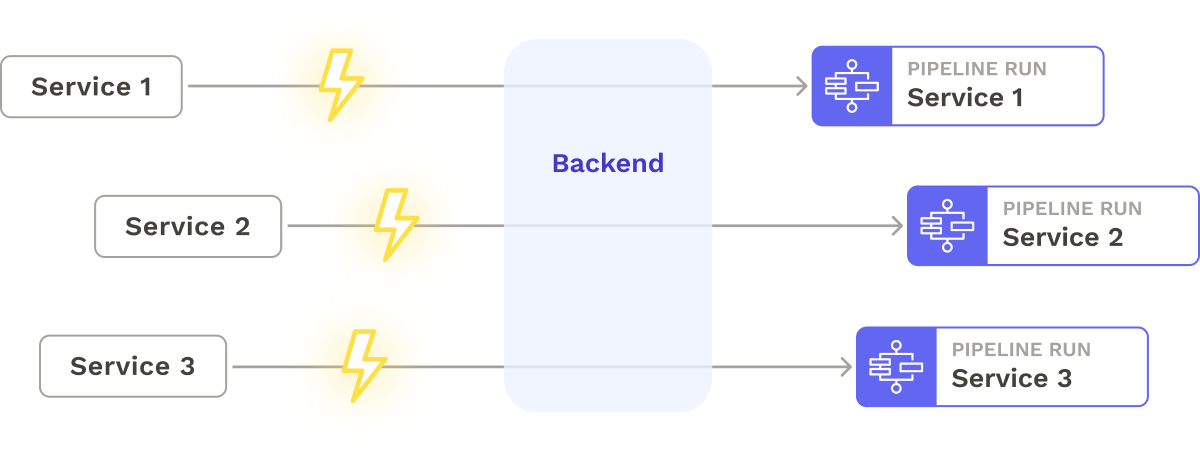
Even though Seamless is designed for smaller companies, we designed our infrastructure to support the growth of such companies, whether it be adding more microservices or hiring more developers and making more commits. For instance, we evaluated the possibility of many changes being made to many microservices at once. Consider a scenario where ten microservices each initiate five new pull requests simultaneously; in such a case, Seamless's infrastructure would have to contend with managing fifty concurrent pipeline executions. To tackle this challenge, we developed Seamless to manage high volumes of pipeline executions.
Parallel Execution of State Machines
Firstly, Seamless enables parallel execution of state machines by utilizing separate instances of AWS Step Functions. This allows for concurrent execution, enabling different microservices to use the shared pipeline simultaneously.
Serverless Backend
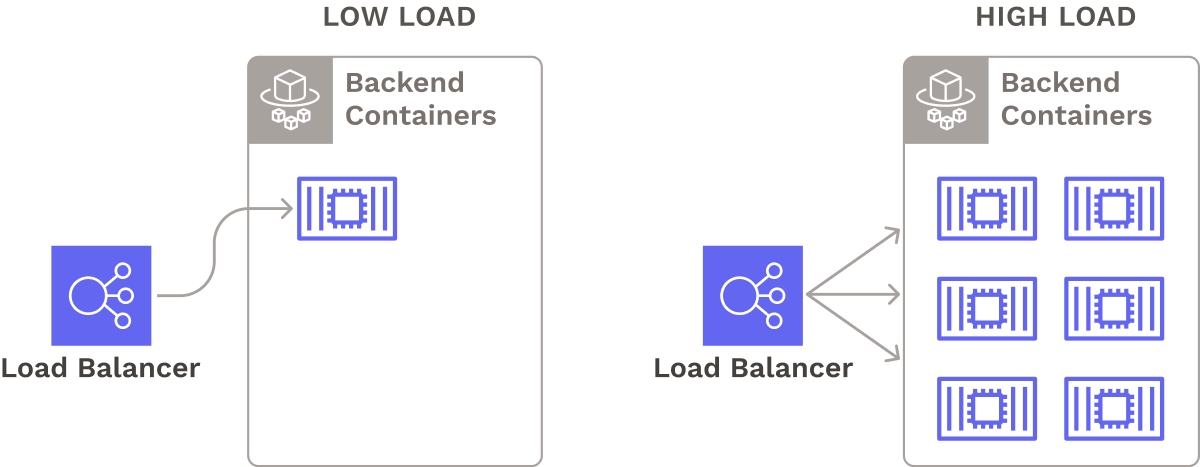
Seamless’s backend processes all status updates and logs generated by the pipeline. If there are many concurrent pipeline runs, the backend server could receive a high load of logs and status updates. As a result, we host our containerized backend on AWS’s serverless container engine, ECS Fargate to spin up as many containers as needed in response to demand, without sacrificing performance. We set up a load balancer to evenly distribute traffic among these containers.
5.2 Basic Security
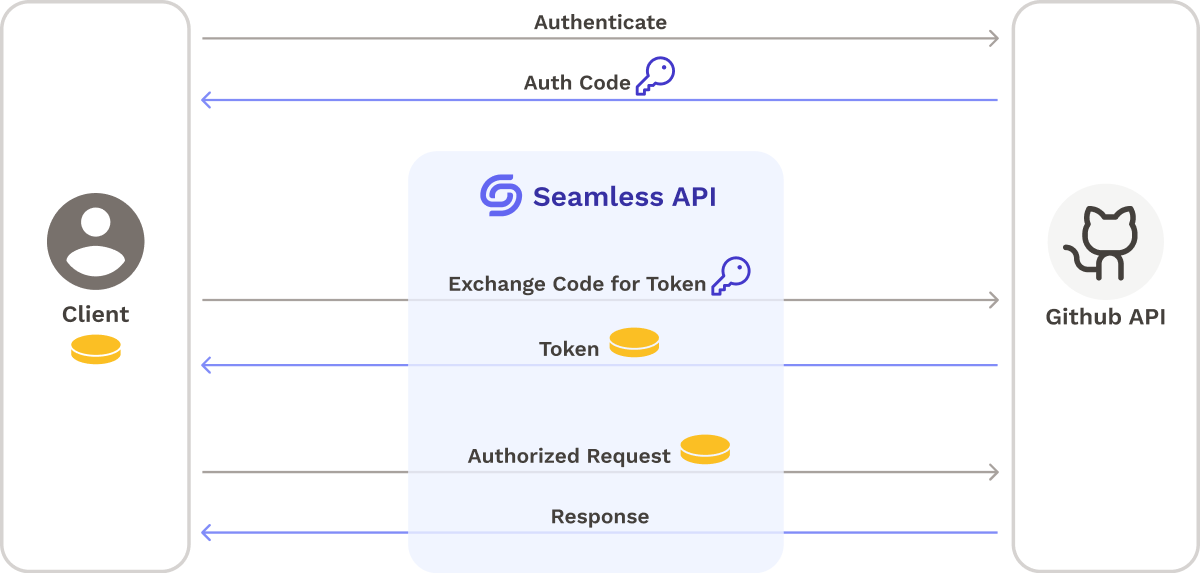
OAuth
Seamless needs secure access to the user’s Github account to perform authorized actions, such as configuring webhooks and cloning their private repositories. To avoid exposing user credentials to Seamless, Seamless retrieves an access token using Github’s OAuth implementation. The flow looks like this:
- When a user logs in to Seamless, they authenticate with Github, which sends back a temporary code.
- The user (client) passes that code to Seamless’s backend, which proxies the code to GitHub.
- Github responds with an access token, which Seamless’s backend sends to the client.
The access token generated during the OAuth flow can then be used by Seamless’s backend to:
- Configure webhooks on the user’s behalf.
- Clone the user’s repositories during state machine execution.
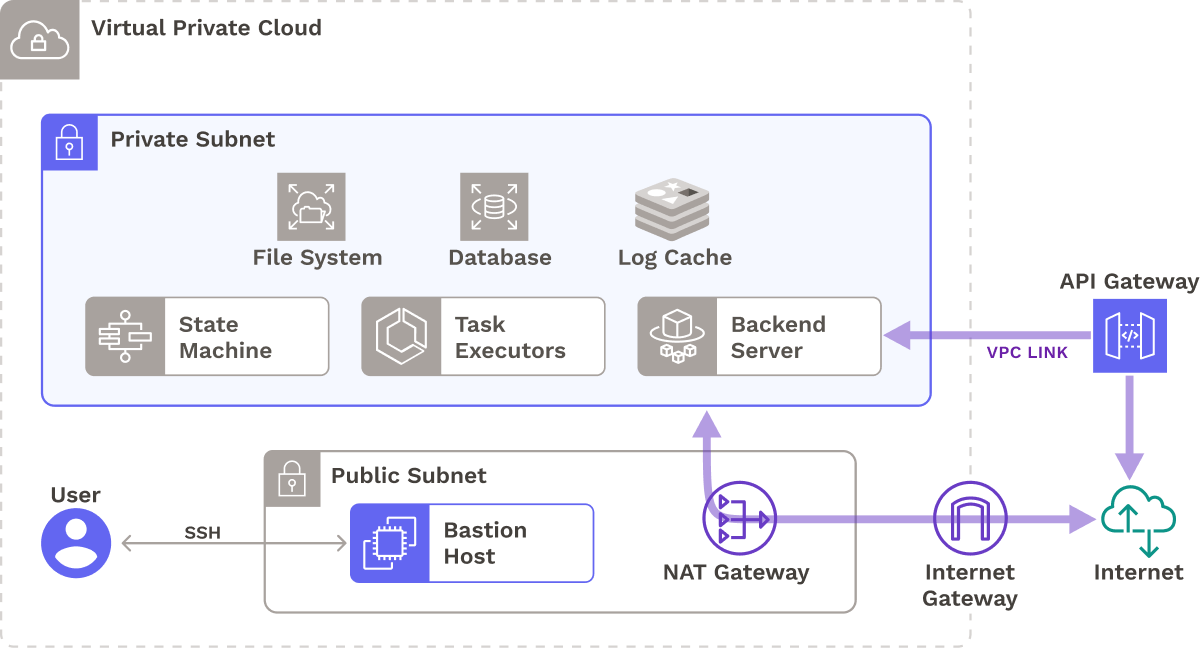
Private Subnets
We also wanted to prevent direct network access to Seamless’s infrastructure, aside from its public-facing API. As a result, we provisioned most of Seamless’s infrastructure in private subnets so they can’t accept incoming network traffic. In case a developer needs to interact with resources in private subnets, such as their relational database or Redis cache, we deploy a bastion host in a public subnet that a developer can SSH into.
Next, let’s look into a few ways Seamless assists in monitoring pipeline executions.
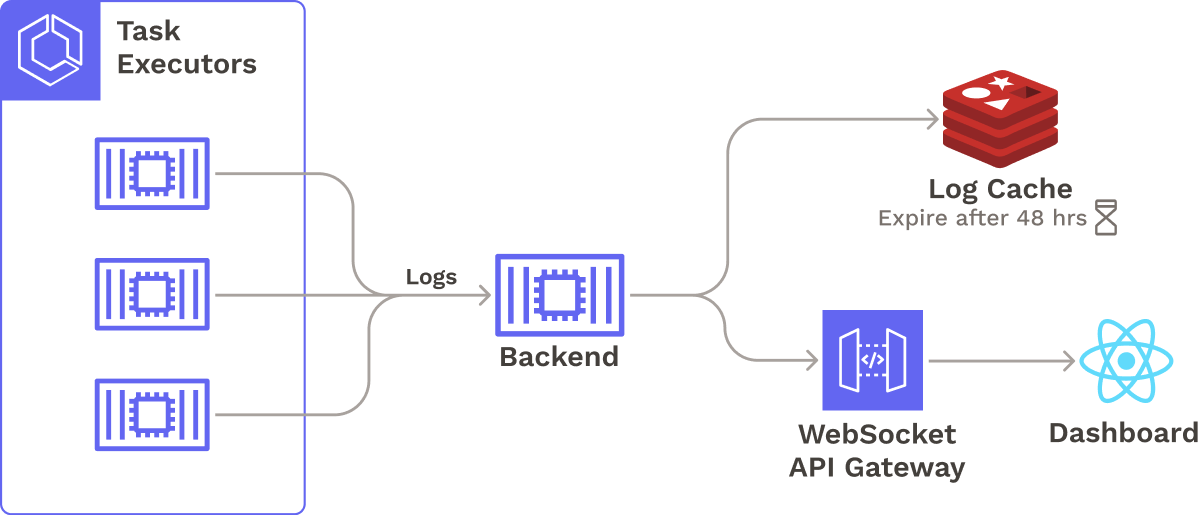
5.3 Logging
If a developer or maintainer were deploying their application manually, they would be able to see logs output from their commands in realtime. For an automated CI/CD pipeline, displaying logs to the user is key to proactively monitoring problems, resolving build and deployment failures, and analyzing test reports.
To integrate logging into Seamless, we first needed a system to capture logs from all task containers. We sought a storage mechanism capable of quickly processing large volumes of logs, and so decided to use a Redis cache (specifically, AWS ElastiCache) due to its high-speed, in-memory data storage capabilities.
We needed to display logs in chronologically sorted order. As a result, we decided to use sorted sets to insert logs in sorted order, eliminating the need for sorting when reading logs. Incoming log streams are sent over WebSockets to the dashboard, where they are finally displayed.
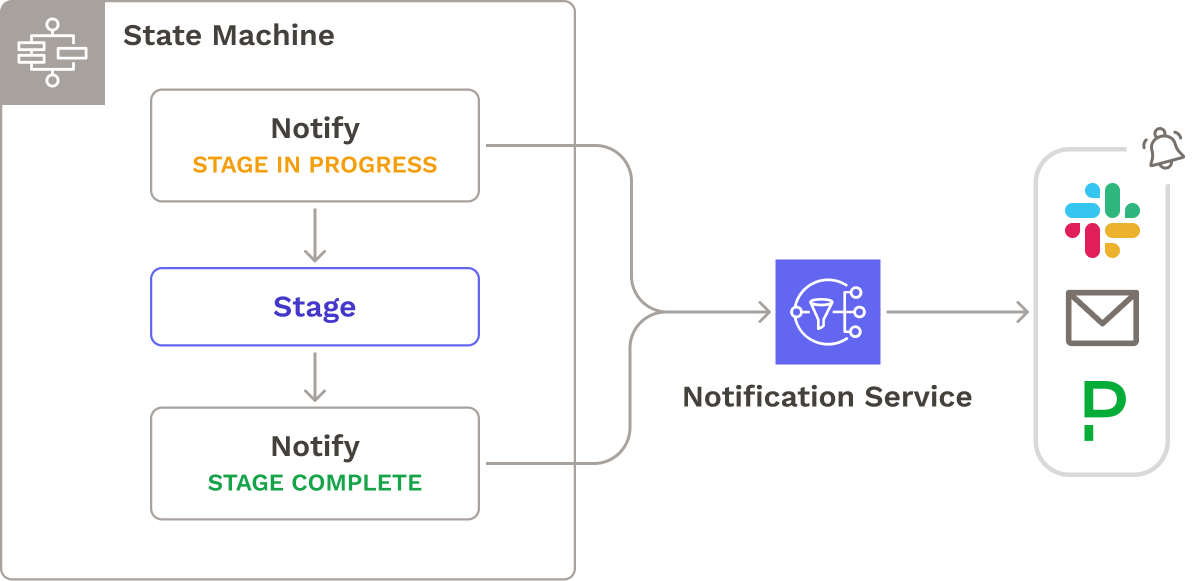
5.4 Notifications
Engineering teams need to stay up-to-date with pipeline execution and quickly address any issues that arise. While users could already monitor their pipeline through the dashboard, we also added notification functionality to Seamless. Seamless offers integration with AWS Simple Notification Service (SNS), allowing for notifications to be sent via email, Slack, and PagerDuty.
6. Conclusion & Future Work
Now that we’ve discussed Seamless’s architecture in depth, let’s put it all together:
- When the source code is updated, GitHub sends a webhook to an API Gateway.
- An Express.js backend running in an ECS Fargate cluster receives the webhook through an HTTP API Gateway.
- The backend retrieves pipeline information from a PostgreSQL database and sends it to the state machine to initiate the pipeline.
- The state machine executes each pipeline task in a container in ECS, which can share data via a mounted volume on Elastic File System (EFS) and access the Elastic Container Registry for pushing or pulling required images.
- The updated source code is deployed to staging and production Fargate clusters.
During the pipeline run, the state machine sends status updates to the backend for storage in the database, and to users via SNS. The task containers send logs to the backend to be inserted into a Redis log cache. The backend sends both status updates and logs to the frontend dashboard via a WebSockets connection maintained by the API Gateway.
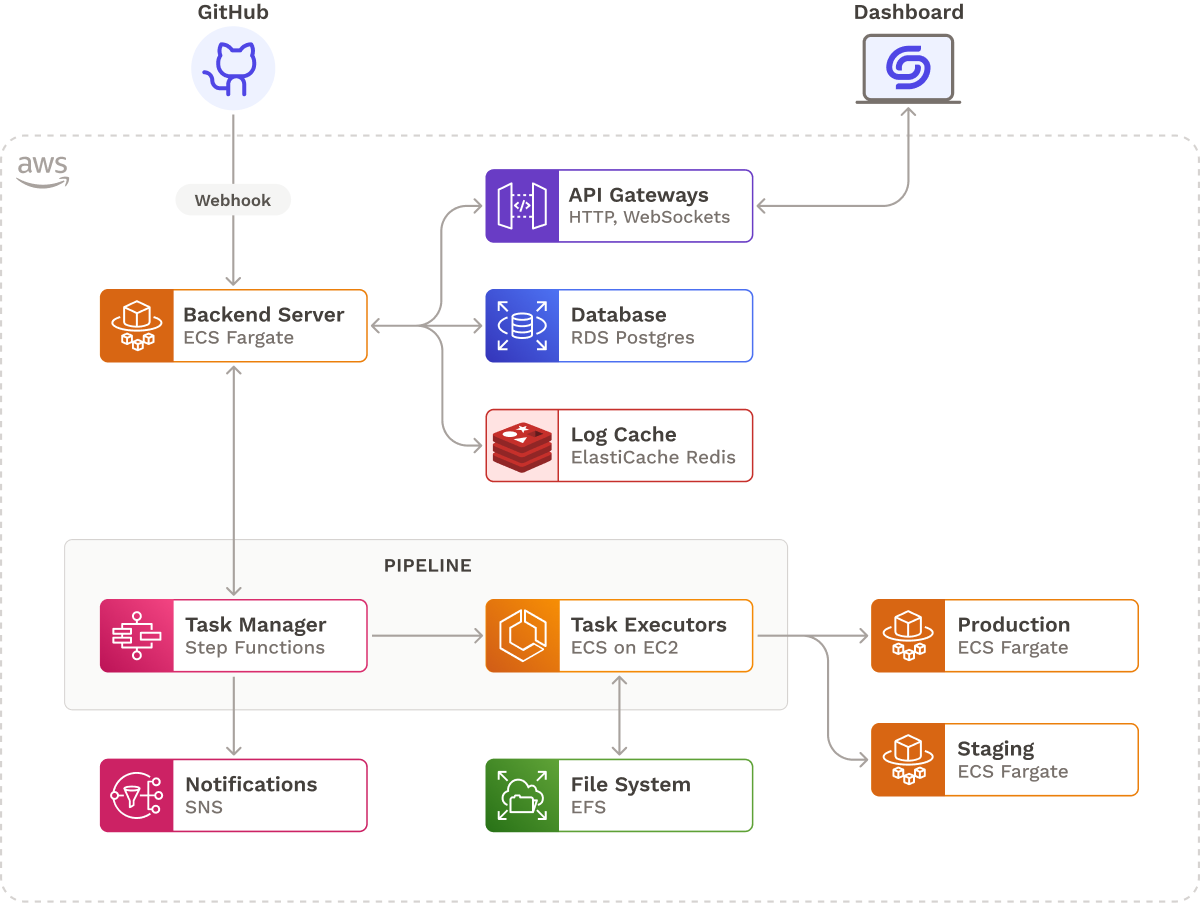
We narrowed down the scope of Seamless for Node-based containerized microservices running on ECS Fargate with similar build, test, and deployment requirements. However, going forward, there are additional features we would like to include and improvements we would like to make to our current implementation.
6.1 Future Work
Seamless could be improved to support more use cases and offer more functionality. Some features we would like to explore are:
- Additional microservice-specific testing options.
- Expanding deployment options beyond ECS Fargate.
- Supporting microservices not built using Node.js.
- Caching dependencies between pipeline executions.
Thank you for taking the time to read our case study!
References
- https://www.cmswire.com/information-management/version-control-systems-the-link-between-development-and-deployment↩
- https://medium.com/driven-by-code/the-journey-to-ci-cd-b1872927c36b↩
- https://hosteddocs.ittoolbox.com/RAW14335USEN-1.pdf↩
- https://medium.com/driven-by-code/the-journey-to-ci-cd-b1872927c36b↩
- https://blog.technologent.com/avoid-these-5-ci/cd-pipeline-challenges↩
- https://semaphoreci.com/blog/cicd-pipeline↩
- https://services.google.com/fh/files/misc/2022_state_of_devops_report.pdf↩
- https://semaphoreci.com/blog/cicd-pipeline↩
- https://learn.microsoft.com/en-us/azure/architecture/example-scenario/apps/devops-dotnet-baseline↩
- https://www.split.io/wp-content/uploads/2022/07/OReilly_Continuous_Delivery.pdf↩
- https://www.atlassian.com/microservices/microservices-architecture/microservices-vs-monolith↩
- https://www.ibm.com/topics/microservices↩
- https://www.youtube.com/watch?v=TAP8vVbsBXQ↩
- https://techbeacon.com/enterprise-it/microservices-containers-operations-guess-whos-responsible-now↩
- https://en.wikipedia.org/wiki/Don't_repeat_yourself↩
- https://www.youtube.com/watch?v=TAP8vVbsBXQ↩
- https://medium.com/containers-101/ci-cd-pipelines-for-microservices-ea33fb48dae0↩
- https://martinfowler.com/articles/microservice-testing↩
- https://martinfowler.com/articles/microservice-testing/#testing-integration-introduction↩
- https://plugins.jenkins.io↩
- https://www.nimblework.com/blog/tekton-reusable-pipelines↩
- https://www.codecapers.com.au/microservices-for-startups-1↩
- https://www.perceptionsystem.com/blog/startups-with-micro-services-architecture↩
- https://www.codecapers.com.au/microservices-for-startups-1↩
- https://codefresh.io/docs/docs/pipelines/introduction-to-codefresh-pipelines/↩